|
|
|
|
Verificación de calidad de datos con Great Expectations
PRECAUCIÓN 😱: El tema presentado en esta sección está clasificado como avanzado. El entendimiento de este contenido es totalmente opcional.
Great Expectations
Great expentations es una libreria en Python y una utilidad de linea de comandos que provee un lenguaje declarativo y flexible para describir nuestras expectativas sobre como los datos deben lucir. Permite validar y documentar la calidad de los datos para luego facilmente comunicar los resultados.
Podemos instalar Great Expectations en Python como sigue:
pip install great_expectations
La librería Great Expectations’ más de 50 expectations ya listas para utilizar:
expect_column_values_to_not_be_nullexpect_column_values_to_match_regexexpect_column_values_to_be_uniqueexpect_column_values_to_match_strftime_formatexpect_table_row_count_to_be_betweenexpect_column_median_to_be_between
Para más información sobre esta librería puede ver su sitio web.
Preparación del notebook
Instalamos las librerías necesarias:
[ ]:
!wget https://raw.githubusercontent.com/santiagxf/E72102/master/docs/develop/prep/code/expectations.txt \
--quiet --no-clobber
!pip install -r expectations.txt
[1]:
import warnings
import ruamel.yaml
warnings.filterwarnings("ignore")
warnings.simplefilter('ignore', ruamel.yaml.error.UnsafeLoaderWarning)
Descargamos los conjuntos de datos:
[2]:
!wget https://raw.githubusercontent.com/santiagxf/E72102/master/docs/develop/prep/code/datasets/nyc_taxi/yellow_tripdata_sample_2019-01.csv \
--quiet --no-clobber --directory-prefix datasets/nyc_taxi/
!wget https://raw.githubusercontent.com/santiagxf/E72102/master/docs/develop/prep/code/datasets/nyc_taxi/yellow_tripdata_sample_2019-02.csv \
--quiet --no-clobber --directory-prefix datasets/nyc_taxi/
Ejemplo
Utilizaremos el conjunto de datos NYC Taxi data. Cada registro en los datos corresponde a un viaje en taxi y contiene información como el lugar donde se toma el taxi y el lugar donde el pasajero se baja del mismo, el monto del pago y el número de pasajeros, entre otros.
Si bien este conjunto de datos es actualizado cada mes, en nuestro caso sólo utilizaremos dos archivos CSV correspondientes a 2 meses, cada uno con una muestra de 10,000 filas del conjunto Yellow Taxi Trip Records:
yellow_tripdata_sample_2019-01.csv: una muestra de los datos de taxis de enero de 2019
yellow_tripdata_sample_2019-02.csv: una muestra de los datos de taxis de febrero de 2019
[3]:
import pandas as pd
import glob
df = pd.concat(map(lambda file: pd.read_csv(file), glob.glob("datasets/nyc_taxi/*.csv")))
df.head(5)
[3]:
| vendor_id | pickup_datetime | dropoff_datetime | passenger_count | trip_distance | rate_code_id | store_and_fwd_flag | pickup_location_id | dropoff_location_id | payment_type | fare_amount | extra | mta_tax | tip_amount | tolls_amount | improvement_surcharge | total_amount | congestion_surcharge | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2019-02-07 15:48:06 | 2019-02-07 16:00:40 | 2 | 1.30 | 1 | N | 234 | 211 | 1 | 9.0 | 2.5 | 0.5 | 2.46 | 0.0 | 0.3 | 14.76 | 2.5 |
| 1 | 2 | 2019-02-11 15:19:56 | 2019-02-11 15:40:10 | 1 | 2.37 | 1 | N | 161 | 249 | 1 | 14.0 | 0.0 | 0.5 | 3.46 | 0.0 | 0.3 | 20.76 | 2.5 |
| 2 | 2 | 2019-02-15 20:03:53 | 2019-02-15 20:08:34 | 1 | 0.48 | 1 | N | 237 | 161 | 1 | 5.0 | 0.5 | 0.5 | 1.50 | 0.0 | 0.3 | 10.30 | 2.5 |
| 3 | 2 | 2019-02-03 15:16:04 | 2019-02-03 15:21:49 | 1 | 0.64 | 1 | N | 100 | 48 | 1 | 5.5 | 0.0 | 0.5 | 1.76 | 0.0 | 0.3 | 10.56 | 2.5 |
| 4 | 2 | 2019-02-15 09:23:09 | 2019-02-15 09:42:51 | 6 | 2.56 | 1 | N | 114 | 230 | 1 | 13.5 | 0.0 | 0.5 | 3.36 | 0.0 | 0.3 | 20.16 | 2.5 |
Configurando Great Expectations
En Great Expectations es necesario crear un contexto de datos para comenzar a trabajar. El contexto administra la configuración del proyecto en el que estamos trabajando. Los contextos de datos permiten reutilizar conjuntos de expectativas, orígenes de datos y puntos de control previamente configurados.
El siguiente código crea un contexto en el directorio /proyecto:
[4]:
import great_expectations as gx
context = gx.get_context(mode="file", project_root_dir="proyecto")
Una vez creado, podemos obtener información al respecto:
[5]:
print(context)
{
"checkpoint_store_name": "checkpoint_store",
"config_variables_file_path": "uncommitted/config_variables.yml",
"config_version": 4.0,
"data_context_id": "c0a6adb8-2e0c-4dde-8083-569c9fba0969",
"data_docs_sites": {
"local_site": {
"class_name": "SiteBuilder",
"show_how_to_buttons": true,
"store_backend": {
"class_name": "TupleFilesystemStoreBackend",
"base_directory": "uncommitted/data_docs/local_site/"
},
"site_index_builder": {
"class_name": "DefaultSiteIndexBuilder"
}
}
},
"expectations_store_name": "expectations_store",
"fluent_datasources": {},
"plugins_directory": "plugins/",
"stores": {
"expectations_store": {
"class_name": "ExpectationsStore",
"store_backend": {
"class_name": "TupleFilesystemStoreBackend",
"base_directory": "expectations/"
}
},
"validation_results_store": {
"class_name": "ValidationResultsStore",
"store_backend": {
"class_name": "TupleFilesystemStoreBackend",
"base_directory": "uncommitted/validations/"
}
},
"checkpoint_store": {
"class_name": "CheckpointStore",
"store_backend": {
"class_name": "TupleFilesystemStoreBackend",
"suppress_store_backend_id": true,
"base_directory": "checkpoints/"
}
},
"validation_definition_store": {
"class_name": "ValidationDefinitionStore",
"store_backend": {
"class_name": "TupleFilesystemStoreBackend",
"base_directory": "validation_definitions/"
}
}
},
"validation_results_store_name": "validation_results_store"
}
Conectandose a origenes de datos
Librerias empresariales suelen utilizar el concepto de fuente de datos para acceder a la información. Como vimos en adquisición de datos, existen multiples plataformas donde esta información puede residir. En general, debe familiarizarce con 3 ideas:
Origen de datos
Conjunto de datos
Batch de datos
Para este ejemplo, utilizaremos datos que se encuentran en un conjunto de datos en formato CSV.
Primero, defina los parámetros de la fuente de datos. La siguiente fuente de datos lee información de un directorio local llamado datasets. Otros origenes de datos podrían ser bases de datos de SQL o motores de datos como Spark.
[6]:
source_folder = "./datasets"
data_source_name = "datasets"
[7]:
data_source = context.data_sources.add_or_update_pandas_filesystem(
name=data_source_name, base_directory=source_folder
)
Luego, definamos un conjunto de datos dentro del origen:
[8]:
asset_name = "nyc_taxi"
data_directory = "./nyc_taxi/*.csv"
[9]:
directory_csv_asset = data_source.add_csv_asset(
name=asset_name, glob_directive=data_directory
)
Cuando los origenes de datos son grandes, leer los datos de forma cuidadosa es importante. Great Expectations usa la idea de sets de información (batch).
Usted puede estar familiarizado con leer todos los datos de una sola vez cuando hace, por ejemplo, pandas.read_csv. Lo mismo lo podría hacer de la siguiente forma:
[10]:
batch_definition = directory_csv_asset.add_batch_definition(
name="all_records"
)
[11]:
batch = batch_definition.get_batch()
batch.head()
[11]:
vendor_id pickup_datetime dropoff_datetime passenger_count \
0 1 2019-02-07 15:48:06 2019-02-07 16:00:40 2
1 2 2019-02-11 15:19:56 2019-02-11 15:40:10 1
2 2 2019-02-15 20:03:53 2019-02-15 20:08:34 1
3 2 2019-02-03 15:16:04 2019-02-03 15:21:49 1
4 2 2019-02-15 09:23:09 2019-02-15 09:42:51 6
trip_distance rate_code_id store_and_fwd_flag pickup_location_id \
0 1.30 1 N 234
1 2.37 1 N 161
2 0.48 1 N 237
3 0.64 1 N 100
4 2.56 1 N 114
dropoff_location_id payment_type fare_amount extra mta_tax tip_amount \
0 211 1 9.0 2.5 0.5 2.46
1 249 1 14.0 0.0 0.5 3.46
2 161 1 5.0 0.5 0.5 1.50
3 48 1 5.5 0.0 0.5 1.76
4 230 1 13.5 0.0 0.5 3.36
tolls_amount improvement_surcharge total_amount congestion_surcharge
0 0.0 0.3 14.76 2.5
1 0.0 0.3 20.76 2.5
2 0.0 0.3 10.30 2.5
3 0.0 0.3 10.56 2.5
4 0.0 0.3 20.16 2.5
En general, esta forma de leer datos no le parecerá con sentido alguno. Y es que Great Expectations diseña estas modalidades para cuando la lectura de datos tiene que ser mas cuidadosa. Por ejemplo, puede leer datos basado en:
Una partición de los datos, como un cliente, una provincia, o un pais.
Una fecha en particular o rango, incluyendo año, mes, dia, o tiempo.
Un directorio o estructura de directios en particular.
Diseñando expectativas
Para diseñar nuestras expectativas, una de las formas más sencillas es realizarlo de forma interactiva, donde podemos ir validando las mismas a medida que las diseñamos:
Cuando ejecutamos una expectativa, se validará inmediatamente con el conjunto de datos. El objeto que devuelve este método contendrá el resultado y una lista de valores que no cumplen con la expectativa. Esta información nos ayuda a concentrarnos en datos que no esperamos tener muy rápidamente, eliminando muchas conjeturas de la exploración de datos.
La siguiente expectativa indica que la cantidad de pasajeros del viaje debe ser al menos 1.
[13]:
preset_expectation = gx.expectations.ExpectColumnMaxToBeBetween(
column="passenger_count", min_value=1
)
Podemos validar una expectativa sobre un lote de datos, donde la misma a tenido éxito (success=true)
[14]:
batch.validate(preset_expectation)
[14]:
{
"success": true,
"expectation_config": {
"type": "expect_column_max_to_be_between",
"kwargs": {
"batch_id": "datasets-nyc_taxi",
"column": "passenger_count",
"min_value": 1.0
},
"meta": {}
},
"result": {
"observed_value": 6
},
"meta": {},
"exception_info": {
"raised_exception": false,
"exception_traceback": null,
"exception_message": null
}
}
Modifiquemos la expectativa e indiquemos que la cantidad máxima de pasajeros es 6:
[15]:
preset_expectation = gx.expectations.ExpectColumnMaxToBeBetween(
column="passenger_count", min_value=1, max_value=6
)
[16]:
batch.validate(preset_expectation)
[16]:
{
"success": true,
"expectation_config": {
"type": "expect_column_max_to_be_between",
"kwargs": {
"batch_id": "datasets-nyc_taxi",
"column": "passenger_count",
"min_value": 1.0,
"max_value": 6.0
},
"meta": {}
},
"result": {
"observed_value": 6
},
"meta": {},
"exception_info": {
"raised_exception": false,
"exception_traceback": null,
"exception_message": null
}
}
Es común encontrar problemas de datos donde no es necesario garantizar el 100% de adherencia. En estos casos, considere usar un parámetro mostly. Este parámetro es una opción para todas las Expectativas y permite controlar el nivel de margen tolerancia en el que la expectativa podría no cumplirse. Mire como en el próximo ejemplo, el parametro mostly hace que la expecativa retorne true en la propiedad success:
[21]:
preset_expectation = gx.expectations.ExpectColumnValuesToNotBeNull(
column="vendor_id", mostly=0.9
)
[22]:
batch.validate(preset_expectation)
[22]:
{
"success": true,
"expectation_config": {
"type": "expect_column_values_to_not_be_null",
"kwargs": {
"batch_id": "datasets-nyc_taxi",
"column": "vendor_id",
"mostly": 0.9
},
"meta": {}
},
"result": {
"element_count": 10000,
"unexpected_count": 0,
"unexpected_percent": 0.0,
"partial_unexpected_list": [],
"partial_unexpected_counts": [],
"partial_unexpected_index_list": []
},
"meta": {},
"exception_info": {
"raised_exception": false,
"exception_traceback": null,
"exception_message": null
}
}
Podemos también agregar documentación a nuestras expectativas para futura referencia:
[24]:
preset_expectation = gx.expectations.ExpectColumnMaxToBeBetween(
column="passenger_count", min_value=1, max_value=6,
meta = {
"notes": {
"content": [ "Todos los viajes deben tener al menos un pasajero." ],
"format": "markdown",
"source": "expectations"
}
}
)
Podemos crear expectativas dentro de una suite, que luego se ejecuten todas al mismo tiempo.
[ ]:
expectation_suite_name = 'yellow_tripdata_sample_quality'
suite = gx.ExpectationSuite(name=expectation_suite_name)
[28]:
suite.add_expectation(gx.expectations.ExpectColumnValuesToBeInSet(column="store_and_fwd_flag", value_set=['Y', 'N'],
meta = {
"notes": {
"content": [ "Acepta valores de Si y No." ],
"format": "markdown",
"source": "expectations"
}
}))
suite.add_expectation(gx.expectations.ExpectColumnValuesToBeInSet(column="payment_type", value_set=[1, 2, 3, 4],
meta = {
"notes": {
"content": [ "Solo formas de pago 1, 2, 3, y 5 son validas" ],
"format": "markdown",
"source": "expectations"
}
}))
suite.add_expectation(gx.expectations.ExpectColumnPairValuesAToBeGreaterThanB(column_A="dropoff_datetime",
column_B="pickup_datetime",
or_equal=True,
meta = {
"notes": {
"content": [ "Las fechas de inicio y fin de viaje deben coincidir." ],
"format": "markdown",
"source": "expectations"
}
})
)
print("Listo")
Listo
[31]:
suite = context.suites.add_or_update(suite)
suite.save()
Validadores
Los validadores le permite configurar una determinada suite sobre un conjunto de datos en particular.
[32]:
definition_name = "my_validation_definition"
validation_definition = gx.ValidationDefinition(
data=batch_definition, suite=suite, name=definition_name
)
Guardemos el validador en el contexto:
[ ]:
validation_definition = context.validation_definitions.add(validation_definition)
Ejecutemos el validador:
[33]:
validation_results = validation_definition.run()
[35]:
print(validation_results)
{
"success": true,
"results": [
{
"success": true,
"expectation_config": {
"type": "expect_column_values_to_be_in_set",
"kwargs": {
"batch_id": "datasets-nyc_taxi",
"column": "store_and_fwd_flag",
"value_set": [
"Y",
"N"
]
},
"meta": {
"notes": {
"content": [
"Acepta valores de Si y No."
],
"format": "markdown",
"source": "expectations"
}
},
"id": "83065803-b50c-4cde-ad79-a975e7213c29"
},
"result": {
"element_count": 10000,
"unexpected_count": 0,
"unexpected_percent": 0.0,
"partial_unexpected_list": [],
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_percent_total": 0.0,
"unexpected_percent_nonmissing": 0.0,
"partial_unexpected_counts": [],
"partial_unexpected_index_list": []
},
"meta": {},
"exception_info": {
"raised_exception": false,
"exception_traceback": null,
"exception_message": null
}
},
{
"success": true,
"expectation_config": {
"type": "expect_column_values_to_be_in_set",
"kwargs": {
"batch_id": "datasets-nyc_taxi",
"column": "payment_type",
"value_set": [
1,
2,
3,
4
]
},
"meta": {
"notes": {
"content": [
"Solo formas de pago 1, 2, 3, y 5 son validas"
],
"format": "markdown",
"source": "expectations"
}
},
"id": "99afda73-92e4-4865-9d1d-1ca8556da0b2"
},
"result": {
"element_count": 10000,
"unexpected_count": 0,
"unexpected_percent": 0.0,
"partial_unexpected_list": [],
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_percent_total": 0.0,
"unexpected_percent_nonmissing": 0.0,
"partial_unexpected_counts": [],
"partial_unexpected_index_list": []
},
"meta": {},
"exception_info": {
"raised_exception": false,
"exception_traceback": null,
"exception_message": null
}
},
{
"success": true,
"expectation_config": {
"type": "expect_column_pair_values_a_to_be_greater_than_b",
"kwargs": {
"batch_id": "datasets-nyc_taxi",
"column_A": "dropoff_datetime",
"column_B": "pickup_datetime",
"or_equal": true
},
"meta": {
"notes": {
"content": [
"Las fechas de inicio y fin de viaje deben coincidir."
],
"format": "markdown",
"source": "expectations"
}
},
"id": "ea2514d7-727e-4281-9abd-f0542ebdf878"
},
"result": {
"element_count": 10000,
"unexpected_count": 0,
"unexpected_percent": 0.0,
"partial_unexpected_list": [],
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_percent_total": 0.0,
"unexpected_percent_nonmissing": 0.0,
"partial_unexpected_counts": [],
"partial_unexpected_index_list": []
},
"meta": {},
"exception_info": {
"raised_exception": false,
"exception_traceback": null,
"exception_message": null
}
}
],
"suite_name": "yellow_tripdata_sample_quality",
"suite_parameters": {},
"statistics": {
"evaluated_expectations": 3,
"successful_expectations": 3,
"unsuccessful_expectations": 0,
"success_percent": 100.0
},
"meta": {
"great_expectations_version": "1.5.0",
"batch_spec": {
"path": "datasets/nyc_taxi/yellow_tripdata_sample_2019-02.csv",
"reader_method": "read_csv",
"reader_options": {}
},
"batch_markers": {
"ge_load_time": "20250609T193750.726883Z",
"pandas_data_fingerprint": "88b447d903f05fb594b87b13de399e45"
},
"active_batch_definition": {
"datasource_name": "datasets",
"data_connector_name": "fluent",
"data_asset_name": "nyc_taxi",
"batch_identifiers": {
"path": "nyc_taxi/yellow_tripdata_sample_2019-02.csv"
},
"batching_regex": "(?P<path>.*)"
},
"validation_id": "a798f47f-fa72-457a-9083-ab77057e8823",
"checkpoint_id": null,
"run_id": {
"run_name": null,
"run_time": "2025-06-09T19:37:51.090303+00:00"
},
"validation_time": "2025-06-09T19:37:51.090303+00:00",
"batch_parameters": null
},
"id": null
}
Construyendo la documentación de expectativas
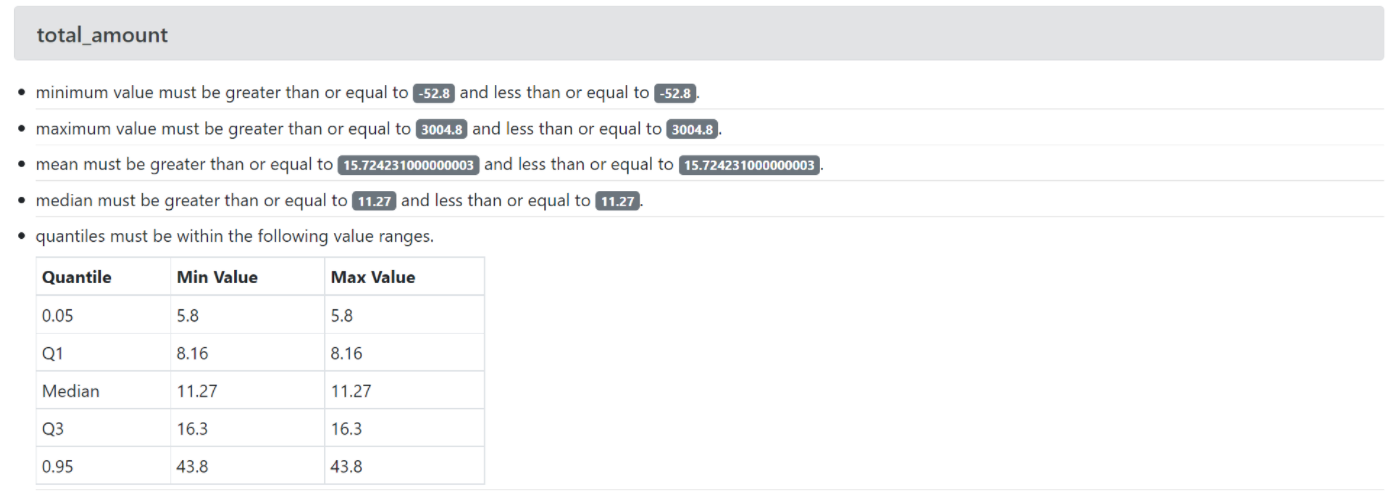
Una forma más amena de explorar estas expectativas es construyendo su documentación. Esta documentación se genera automáticamente leyendo las expectativas de los datos que se generaron. Esto es una excelente forma de comunicar a los diferentes equipos de la organización lo que pueden esperar de estos datos:
Configure la generación del sitio. Cambie el parametro base_directory con el directorio donde desea guardar los archivos:
[44]:
site_name = "NYCTaxi"
site_config = {
"class_name": "SiteBuilder",
"site_index_builder": {"class_name": "DefaultSiteIndexBuilder"},
"store_backend": {
"class_name": "TupleFilesystemStoreBackend",
"base_directory": "docs",
},
}
Agregue la configuración:
[47]:
context.add_data_docs_site(site_name=site_name, site_config=site_config)
Cree el sitio:
[48]:
context.build_data_docs(site_names=site_name)
[48]:
{'NYCTaxi': 'file:///content/proyecto/gx/docs/index.html'}
Puede abrir el sitio web en su navegador o agregarlo al repositorio de código con el que esté trabajando. Si está trabajando en Google Colab, descargue el contenido de la carpeta /content/proyecto/gx/docs
[43]:
context.open_data_docs()
Por ejemplo, la siguiente documentación se genera automáticamente: