|
|
|
|
Creando rutinas de preprocesamiento con Scikit-Learn
Introducción
Las tareas de preprocesamiento de datos pueden ser largas y tediosas. Sin embargo, esto no es el único problema. Si no se realizan de la forma correcta, en muchos casos se pueden introducir problemas de modelado que son dificiles de detectar y que invalidan cualquier técnica de aprendizaje automático que utilicemos luego.
En esta sección aprenderemos varias formas de realizar preprocesamiento y finalmente una forma de empaquetar estas transformaciones de forma que luego sean reproducibles.
Instalación
Necesitaremos instalar las librerias:
[1]:
!pip install ydata_profiling cloudpickle scikit-learn pandas numpy --quiet
Sobre el conjunto de datos del censo UCI
El conjunto de datos del censo de la UCI es un conjunto de datos en el que cada registro representa a una persona. Cada registro contiene 14 columnas que describen a una una sola persona, de la base de datos del censo de Estados Unidos de 1994. Esto incluye información como la edad, el estado civil y el nivel educativo. La tarea es determinar si una persona tiene un ingreso alto (definido como ganar más de $50 mil al año). Esta tarea, dado el tipo de datos que utiliza, se usa a menudo en el estudio de equidad, en parte debido a los atributos comprensibles del conjunto de datos, incluidos algunos que contienen tipos sensibles como la edad y el género, y en parte también porque comprende una tarea claramente del mundo real.
Descargamos el conjunto de datos
[4]:
!wget https://santiagxf.blob.core.windows.net/public/datasets/uci_census.zip \
--quiet --no-clobber
!mkdir -p datasets/uci_census
!unzip -qq uci_census.zip -d datasets/uci_census
Lo importamos
[5]:
import pandas as pd
import numpy as np
train = pd.read_csv('datasets/uci_census/data/adult-train.csv')
test = pd.read_csv('datasets/uci_census/data/adult-test.csv')
[6]:
train
[6]:
| income | age | workclass | fnlwgt | education | education-num | marital-status | occupation | relationship | race | gender | capital-gain | capital-loss | hours-per-week | native-country | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | <=50K | 39 | State-gov | 77516 | Bachelors | 13 | Never-married | Adm-clerical | Not-in-family | White | Male | 2174 | 0 | 40 | United-States |
| 1 | <=50K | 50 | Self-emp-not-inc | 83311 | Bachelors | 13 | Married-civ-spouse | Exec-managerial | Husband | White | Male | 0 | 0 | 13 | United-States |
| 2 | <=50K | 38 | Private | 215646 | HS-grad | 9 | Divorced | Handlers-cleaners | Not-in-family | White | Male | 0 | 0 | 40 | United-States |
| 3 | <=50K | 53 | Private | 234721 | 11th | 7 | Married-civ-spouse | Handlers-cleaners | Husband | Black | Male | 0 | 0 | 40 | United-States |
| 4 | <=50K | 28 | Private | 338409 | Bachelors | 13 | Married-civ-spouse | Prof-specialty | Wife | Black | Female | 0 | 0 | 40 | Cuba |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 32556 | <=50K | 27 | Private | 257302 | Assoc-acdm | 12 | Married-civ-spouse | Tech-support | Wife | White | Female | 0 | 0 | 38 | United-States |
| 32557 | >50K | 40 | Private | 154374 | HS-grad | 9 | Married-civ-spouse | Machine-op-inspct | Husband | White | Male | 0 | 0 | 40 | United-States |
| 32558 | <=50K | 58 | Private | 151910 | HS-grad | 9 | Widowed | Adm-clerical | Unmarried | White | Female | 0 | 0 | 40 | United-States |
| 32559 | <=50K | 22 | Private | 201490 | HS-grad | 9 | Never-married | Adm-clerical | Own-child | White | Male | 0 | 0 | 20 | United-States |
| 32560 | >50K | 52 | Self-emp-inc | 287927 | HS-grad | 9 | Married-civ-spouse | Exec-managerial | Wife | White | Female | 15024 | 0 | 40 | United-States |
32561 rows × 15 columns
Análisis exploratorio de datos
El análisis exploratorio de datos en la actualidad suele realizarce en una primera instancia de format automátizada, y luego mas específico.
Utilizando librerias de EDA
Existen multiples librerías que automatizan el análisis exploratorio de datos. En esta sección veremos 2:
YData
[8]:
from ydata_profiling import ProfileReport
profile = ProfileReport(train, title="Perfil automático de los datos")
Improve your data and profiling with ydata-sdk, featuring data quality scoring, redundancy detection, outlier identification, text validation, and synthetic data generation.
Hay dos formas de consumir el reporte de esta libreria: Utilizando widgets en notebooks de Jupyter o como un reporte HTML. El siguiente ejemplo muestra como mostrarlo dentro del notebook:
profile.to_widgets()
Google Colab no soporta el uso de este tipo de widgets actualmente. En este caso, es recomendable utilizar reportes en HTML, el cual puede generar con el siguiente código:
[10]:
profile.to_notebook_iframe()
Una de las ventajas de tener el reporte como HTML es que puede exportarlo facilmente para compartirlo:
[ ]:
profile.to_file("reporte.html")
La exploración automática puede ser costosa computacionalmente. Dependiendo del escenario o la cantidad de datos, puede ser que necesite configurar la exploración automática de una forma específica. La librería ofrece detallada documentación para configurar el proceso. El siguiente ejemplo muestra por ejemplo como generar el reporte sin computar la correlación entre todas las variables.
[11]:
profile = train.profile_report(
title="Report without correlations",
correlations=None,
)
Lux
Lux es una biblioteca de Python que facilita la exploración de datos rápida y fácil al automatizar el proceso de visualización y análisis de datos. Al imprimir simplemente un dataframe en un cuaderno de Jupyter, Lux recomienda un conjunto de visualizaciones que destacan tendencias y patrones interesantes en el conjunto de datos.
[13]:
%pip install lux --quiet
Cuando se imprime el dataframe, Lux recomienda automáticamente un conjunto de visualizaciones que destacan tendencias y patrones interesantes en el conjunto de datos.
IMPORTANTE: Google Collab no soporta el uso de la librería LUX. Utilice Binder.
[ ]:
train
Utilizando código
Muchas veces es útil generar nuestras propias rutinas de descripción las cuales se focalizan en las calidades que estamos interesados en monitorear.
Utilizaremos la siguiente rutina para ir verificando los cambios que realizamos en el conjunto de datos. La misma muestra la cantidad de muestras, la cantidad de predictores y algunos valores interesantes en el caso que indiquemos alguna columna para mostrar. Este paso no es necesario en una rutina de preprocesamiento pero simplemente nos ayuda a verificar los cambios que realizamos.
[ ]:
from typing import List, Tuple
def print_stats(df: pd.DataFrame, detail_columns: List[str] = None):
print(f"Muestras:", df.shape[0])
print(f"Features:", df.shape[1])
print(f"Faltantes:", df.isna().sum().sum())
if detail_columns:
print('Detalles:')
for column in detail_columns:
print(f"\tColumna: {column} ({df[column].dtype})")
if df[column].dtype in ['O', 'Object', 'int64']:
print(f"\t\tValores únicos: {len(df[column].unique())}")
print(f"\t\tFaltantes: {df[column].isna().sum()}")
if df[column].dtype in ['float32', 'float64']:
print(f"\t\tMedia: {df[column].mean()}")
Por ejemplo, podemos utilizarla como sigue:
[ ]:
print_stats(train)
Muestras: 32561
Features: 15
Faltantes: 0
[ ]:
import seaborn as sns
import matplotlib.pyplot as plt
[ ]:
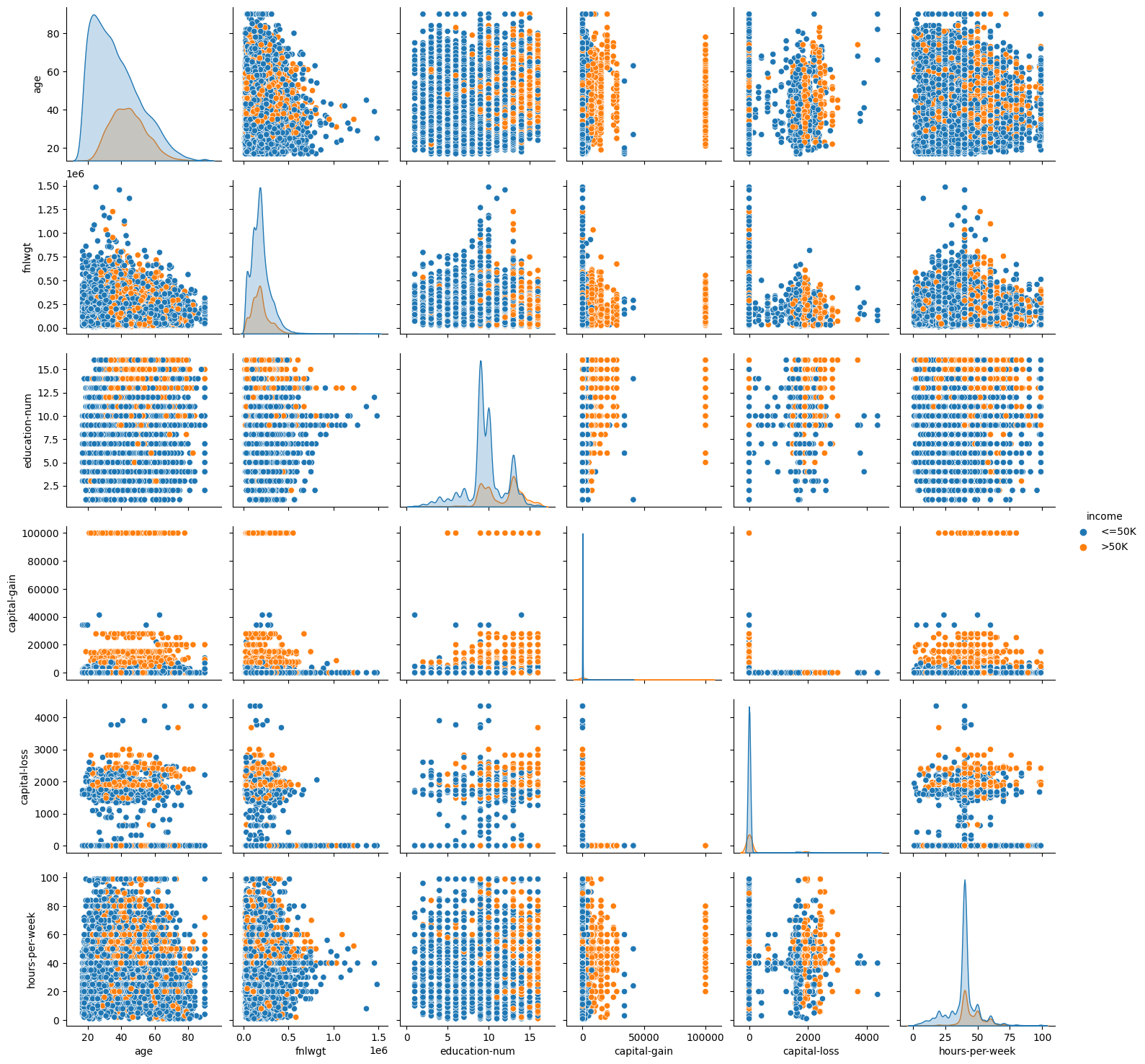
sns.pairplot(train, hue="income")
<seaborn.axisgrid.PairGrid at 0x7f19f4bdecb0>
Creando una rutina de preprocesamiento en el problema censo de la UCI
Veamos como crear una rutina de preprocesamiento para el conjunto de datos del problema de censo de la UCI.
Preprocesando los datos
Veamos a modo de ejemplo multiple preprocesamientos que podemos realizar:
Procesamos valores faltantes
En este conjunto de datos, los valores faltantes estan codifícados muchas veces como «?». Podemos reemplazar este valor por el correspondiente valor faltante para identificarlos mejor:
[ ]:
train.replace(' ?', np.nan, inplace=True)
[ ]:
print_stats(train)
Muestras: 32561
Features: 15
Faltantes: 4262
Corrección calidad de datos
Muchas variables, adicionalmente, tienen el problema que sus valores poseen «espacios» en blanco que son dificiles de divisar. Por ejemplo el valor « married» (note el espacio al principio del texto). Eliminaremos estos espacios en blanco con la función lstrip().
[ ]:
for col in train.dtypes[train.dtypes == 'object' ].keys():
train[col] = train[col].str.lstrip()
Tip: En Numpy, strings son almacenadas como tipo
object.
Corrección de tipos de datos
Algunas variables podríamos necesitarlas en otro tipo de dato. Por ejemplo, podríamos necesitar la variable edad que esté codificada como entera en lugar de como punto flotante:
[ ]:
train["age"] = train["age"].astype(int)
[ ]:
print_stats(train, detail_columns=['age'])
Muestras: 32561
Features: 15
Faltantes: 4262
Detalles:
Columna: age (int64)
Valores únicos: 73
Faltantes: 0
Eliminando registros duplicados
En algunos casos, puede ser util eliminar regitros que son duplicados. En general, la mayoria de los algoritmos de aprendizaje suelen ser robustos a este tipo de características.
[ ]:
train.drop_duplicates(inplace=True)
[ ]:
print_stats(train)
Muestras: 32537
Features: 15
Faltantes: 4261
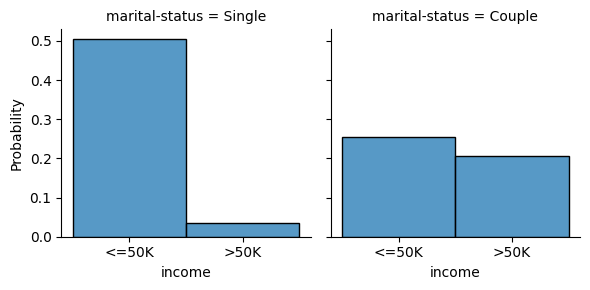
Reagrupando variables categoricas
En algunas ocaciones, algunas variables categóricas que tienen muchos valores pueden introducir un problema de dimensionalidad al codificarlas, especialmente si utilizamos one-hot encoding. Podemos explorar la distribución y identificar si podemos reagruparlas:
[ ]:
sns.displot(train, x="income", stat="probability", col="marital-status", height=3)
<seaborn.axisgrid.FacetGrid at 0x7b8781c934c0>

Agrupamos entonces las diferentes categorías de la siguiente forma:
[ ]:
mapping = {
'Divorced': 'Single',
'Married-spouse-absent': 'Single',
'Never-married': 'Single',
'Separated': 'Single',
'Widowed': 'Single',
'Married-AF-spouse': 'Couple',
'Married-civ-spouse': 'Couple',
}
La función map() nos permite mapear los valores a otro conjunto de valores utilizando un diccionario como entrada:
[ ]:
train['marital-status'] = train['marital-status'].map(mapping)
Verifiquemos la nueva distribución:
[ ]:
sns.displot(train, x="income", stat="probability", col="marital-status", height=3)
<seaborn.axisgrid.FacetGrid at 0x7b87a7ed6020>
Tranformamos columnas a una escala logaritmica
En general, las variables que involugran precios suelen (en algunas ocaciones, mostrar distribuciones exponenciales.
[ ]:
sns.displot(train, x="capital-gain", col="income", height=3)
sns.displot(train, x="capital-loss", col="income", height=3)
<seaborn.axisgrid.FacetGrid at 0x7b8776ed1210>
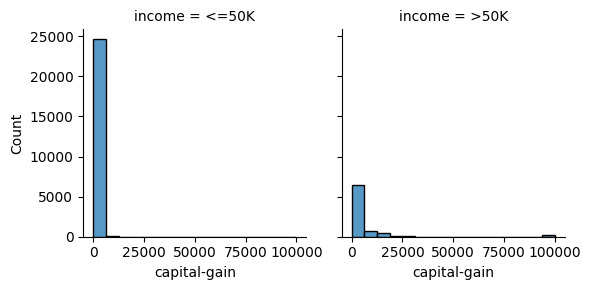
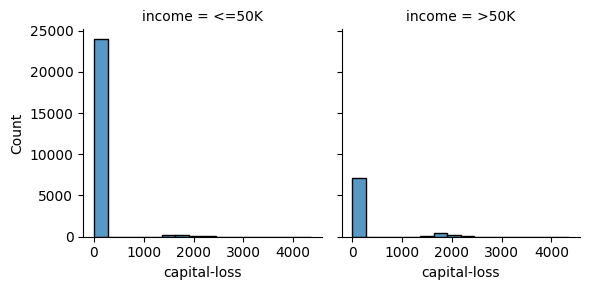
Note que existe una gran cantidad de instancias con valor cero en estas columnas. Podríamos generar una columna indicadora para capturar este hecho si es que el algoritmo de aprendizaje no puede distinguirlo.
Verifiquemos que sucede si aplicamos el logarítmo natural:
[ ]:
train['capital-gain'] = np.log(train['capital-gain'] + 1)
train['capital-loss'] = np.log(train['capital-loss'] + 1)
[ ]:
sns.displot(train[train['capital-gain'] > 0], x="capital-gain", col="income", height=3)
sns.displot(train[train['capital-loss'] > 0], x="capital-loss", col="income", height=3)
<seaborn.axisgrid.FacetGrid at 0x7b8776e12e30>
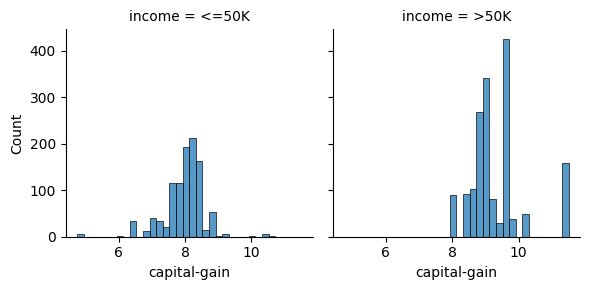
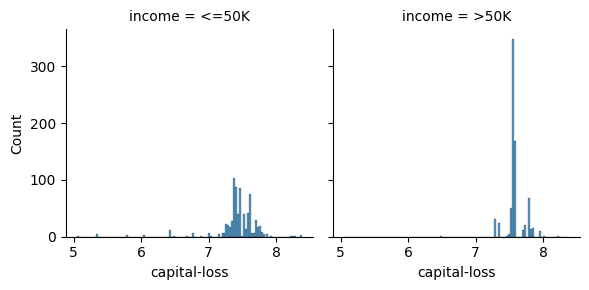
Veamos que tenemos distribuciones que resultan mucho más informativas.
Eliminamos valores faltantes en la columna a predecir
Los valores faltantes en la columna a predecir no pueden ser inputados, y por lo tanto suelen ser eliminados directamente del conjunto de datos:
[ ]:
train.dropna(axis='index', subset=['income'], inplace=True)
[ ]:
print_stats(train)
Muestras: 32537
Features: 15
Faltantes: 4261
Imputar valores faltantes en los predictores
En los predictores, generalmente no queremos eliminar las muestras que continen valores faltantes - a menos que la cantidad de valores faltantes sea alta - ya sea en la fila o en la columna. Por lo tanto, intentaremos imputarlos.
La libraría scikit-learn provee una clase llamada SimpleImputer que nos permite realizar esta operación:
[ ]:
from sklearn.impute import SimpleImputer
Para imputar valores faltantes, en general debemos distinguir si las variables son discretas o continuas:
[ ]:
discrete_feat = train.dtypes[train.dtypes == 'object' ].keys().drop("income")
continuous_feat = train.dtypes[train.dtypes != 'object'].keys()
Tip: Note como las variables discretas no incluyen la columna a predecir.
Variables continuas
Para las variables continuas o numéricas, tenemos varias operaciones con las que podemos computar los valores faltantes. La mejor opción dependerá del problema puntual. En este caso, utilizaremos la media de cada predictor.
[ ]:
for feat in continuous_feat:
imputer = SimpleImputer(strategy='median')
train[feat] = imputer.fit_transform(train[feat].values.reshape(-1,1)).reshape(-1)
Tip: El método
fit_transformrequiere de una matríz como entrada. Al utilizarreshape(-1,1)estamos transformando un vector unidemnsional en una matriz. Luego, el métodoreshape(-1)realiza la operación inversa.
[ ]:
print_stats(train)
Muestras: 32537
Features: 15
Faltantes: 4261
Variables discretas
En las variables discretas no podemos computar la media ya que no está definida. Sin embargo, podemos utilizar el valor más frecuente.
[ ]:
for feat in discrete_feat:
imputer = SimpleImputer(strategy='most_frequent')
train[feat] = imputer.fit_transform(train[feat].values.reshape(-1,1)).reshape(-1)
[ ]:
print_stats(train)
Muestras: 32537
Features: 15
Faltantes: 0
Codificación de variables categóricas
La mayoría de los algoritmos de aprendizaje automático no pueden trabajar con variables categóricas y necesitan que las mismas sean codificadas numericamente.
La libraría scikit-learn también ofrece multiples alternativas y estrategias para realizarlo. En nuestro caso utilizaremos one hot encoding.
[ ]:
from sklearn.preprocessing import OneHotEncoder
for feat in discrete_feat:
encoder = OneHotEncoder(handle_unknown='ignore', sparse_output=False)
transformed = encoder.fit_transform(train[feat].values.reshape(-1,1))
train[encoder.get_feature_names_out([feat])] = transformed
Una vez que las variables han sido codificadas, podemos eliminar las columnas originales:
[ ]:
train.drop(columns=discrete_feat, inplace=True)
[ ]:
print_stats(train)
Muestras: 32537
Features: 101
Faltantes: 0
Normalización de variables numéricas
Muchos algoritmos de aprendizaje automático son sencibles a la escala de los predictores que utilizan. La normalización nos permite asgurar que todos los predictores utilicen la misma.
[ ]:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
train[continuous_feat] = scaler.fit_transform(train[continuous_feat])
Verificando los resultados
Veamos como luce nuestro conjunto de datos:
[ ]:
train.head(5)
| income | age | fnlwgt | education-num | capital-gain | capital-loss | hours-per-week | workclass_Federal-gov | workclass_Local-gov | workclass_Never-worked | ... | native-country_Portugal | native-country_Puerto-Rico | native-country_Scotland | native-country_South | native-country_Taiwan | native-country_Thailand | native-country_Trinadad&Tobago | native-country_United-States | native-country_Vietnam | native-country_Yugoslavia | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | <=50K | 0.030390 | -1.063569 | 1.134777 | 2.830199 | -0.22116 | -0.035664 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1 | <=50K | 0.836973 | -1.008668 | 1.134777 | -0.299391 | -0.22116 | -2.222483 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | <=50K | -0.042936 | 0.245040 | -0.420679 | -0.299391 | -0.22116 | -0.035664 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 3 | <=50K | 1.056950 | 0.425752 | -1.198407 | -0.299391 | -0.22116 | -0.035664 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 4 | <=50K | -0.776193 | 1.408066 | 1.134777 | -0.299391 | -0.22116 | -0.035664 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 101 columns
Empaquetando las transformaciones
Todas las transformaciones que acabamos de realizar, deben luego aplicarse a los otros conjuntos de datos: testing, validacion, e incluso a sus datos en producción cuando el modelo se ejecute. ¿Cómo puede asegurar que las transformaciones son exactamente las mismas?¿Cómo puede asegurar sobre todo la utilización de los mismos parámetros, como ser las normalizaciones o la codificación de variables categóricas?.
Una forma de realizarlo es utilizando scikit-learn y empaquetar todas las transformaciones.
Crearemos entonces una función llamada preprocess_uci la cual contendra los pasos que mencionamos anteriormente en una única rutina:
[ ]:
def preprocess_uci(X, y=None):
val = X.copy()
val.replace(' ?', np.nan, inplace=True)
for col in val.dtypes[X.dtypes == 'object' ].keys():
val[col] = val[col].str.lstrip()
if 'marital-status' in val.columns:
mapping = {
'Divorced': 'Single',
'Married-spouse-absent': 'Single',
'Never-married': 'Single',
'Separated': 'Single',
'Widowed': 'Single',
'Married-AF-spouse': 'Couple',
'Married-civ-spouse': 'Couple',
}
val['marital-status'] = val['marital-status'].map(mapping)
if 'capital-gain' in val.columns:
val['capital-gain'] = np.log(val['capital-gain'] + 1)
val['capital-loss'] = np.log(val['capital-loss'] + 1)
return val
Note que esta función no incluye:
Normalización de variables.
Imputación de valores faltantes.
Codificación de variables.
El motivo es que estos pasos requieren de aprender «parametros» para poder aplicarlos. La libraria nos permite realizar estas acciones en lo que se conoce como pipelines. Así entonces, esta función la utilizaremos como uno de los pasos de una rutina de preprocesamiento más grande que adicionalmente escalará los valores y realizará la codificación de variables categóricas. Esta rutina más grande la llamamos «pipeline de preprocesamiento».
Lucira de la siguiente forma:

[ ]:
from typing import Tuple, List
import sklearn
from sklearn.pipeline import Pipeline, FunctionTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
def prepare(X: pd.DataFrame, transformations: sklearn.compose.ColumnTransformer = None) -> Tuple[pd.DataFrame, sklearn.compose.ColumnTransformer]:
"""
Preprocesasa los deferentes valores de un conjunto de datos.
Parameters
----------
X: pd.DataFrame:
Connto de datos a transformar
transformations: sklearn.compose.ComlumnTransformer
Transformaciones que se deben aplicar al conjunto de datos. Si no son indicadas, las mismas son aprendidas desde el conjunto de datos.
Returns: Tuple[pd.DataFrame, sklearn.compose.ColumnTransformer]
Una tupla donde el primer component es el conjunto de datos transformado y el segundo las transformaciones que se aplicaron.
"""
features = {
'discrete': X.dtypes[X.dtypes == 'object' ].index.tolist(),
'continuous': X.dtypes[X.dtypes != 'object'].index.tolist(),
}
preprocessing_func = FunctionTransformer(func=preprocess_uci, feature_names_out='one-to-one')
num_pipe = Pipeline([
('preprocess', preprocessing_func),
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
cat_pipe = Pipeline([
('preprocess', preprocessing_func),
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder(handle_unknown='ignore', sparse_output=False))
])
if transformations is None:
transformations = ColumnTransformer(
[
('continuous_pipe', num_pipe, features['continuous']),
('discrete_pipe', cat_pipe, features['discrete']),
],
remainder='passthrough')
X = transformations.fit_transform(X)
else:
X = transformations.transform(X)
# Las columnas tiene el nombre "<paso del pipeline>__<columna>". Nos quedaremos con la segunda parte
all_features = [feat.split('__')[1] for feat in transformations.get_feature_names_out()]
return pd.DataFrame(X, columns=all_features), transformations
La ventaja de realizar las transformaciones de esta forma es que la función prepare no solo retorna los datos preprocesados sino que también un objeto que contiene cualquier valor que haya sido aprendido del proceso de transformación.
Note que si pasamos como argumento transformations entonces la rutina no aprende ningun coeficiente sino que utiliza los que nosotros le indicamos.
Veamos como esto termina siendo util:
Generando los conjuntos de datos
Generaremos 3 conjuntos de datos: entrenamiento, validación y testing.
[ ]:
train = pd.read_csv('datasets/uci_census/data/adult-train.csv')
test = pd.read_csv('datasets/uci_census/data/adult-test.csv')
[ ]:
from sklearn.model_selection import train_test_split
validation = test
test, _ = train_test_split(test, test_size=0.9, random_state=1234)
Separemos los predictores de la variable a predecir:
[ ]:
X_train = train.drop(['income'], axis=1)
y_train = train['income'].to_numpy()
X_test = test.drop(['income'], axis=1)
y_test = test['income'].to_numpy()
X_val = validation.drop(['income'], axis=1)
y_val = validation['income'].to_numpy()
Necesitamos preprocesar el conjunto de entrenamiento:
[ ]:
X_train_transformed, transformations = prepare(X_train)
Debemos ahora realizar las mismas transoformaciones sobre los otros dos conjuntos. Sin embargo, queremos aplicar los mismos coeficientes que aprendimos del conjunto de entrenamiento. Para ello simplemente pasamos como parametro las transformaciones:
[ ]:
X_test_transformed, _ = prepare(X_test, transformations)
X_val_transformed, _ = prepare(X_val, transformations)
Persisitiendo transformaciones
La ventaja de generar la rutina de preprocesamiento de esta forma es que ahora en transformations, tenemos todas las tranformaciones almacenadas y podemos guardarlas para luego aplicarlas:
[ ]:
import pickle
import cloudpickle
with open('transformations.pkl', 'wb') as f:
cloudpickle.dump(transformations, f)
Podemos cargarlas y aplicarlas a un nuevo conjunto de datos:
[ ]:
with open('transformations.pkl', 'rb') as f:
transoformations = pickle.load(f)
[ ]:
test = pd.read_csv('datasets/uci_census/data/adult-test.csv')
X_test = test.drop(['income'], axis=1)
y_test = test['income'].to_numpy()
[ ]:
X_test_transformed, _ = prepare(X_test, transformations)
[ ]:
X_test_transformed
| age | fnlwgt | education-num | capital-gain | capital-loss | hours-per-week | workclass_Federal-gov | workclass_Local-gov | workclass_Never-worked | workclass_Private | ... | native-country_Portugal | native-country_Puerto-Rico | native-country_Scotland | native-country_South | native-country_Taiwan | native-country_Thailand | native-country_Trinadad&Tobago | native-country_United-States | native-country_Vietnam | native-country_Yugoslavia | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.995706 | 0.350774 | -1.197459 | -0.299271 | -0.221075 | -0.035429 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1 | -0.042642 | -0.947095 | -0.420060 | -0.299271 | -0.221075 | 0.774468 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | -0.775768 | 1.394362 | 0.746039 | -0.299271 | -0.221075 | -0.035429 | 0.0 | 1.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 3 | 0.397233 | -0.279070 | -0.031360 | 3.345796 | -0.221075 | -0.035429 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 4 | -1.508894 | -0.817458 | -0.031360 | -0.299271 | -0.221075 | -0.845327 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 16276 | 0.030671 | 0.242928 | 1.134739 | -0.299271 | -0.221075 | -0.359389 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 16277 | 1.863485 | 1.247055 | -0.420060 | -0.299271 | -0.221075 | -0.035429 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 16278 | -0.042642 | 1.754690 | 1.134739 | -0.299271 | -0.221075 | 0.774468 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 16279 | 0.397233 | -1.003212 | 1.134739 | 3.206033 | -0.221075 | -0.035429 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 16280 | -0.262580 | -0.072293 | 1.134739 | -0.299271 | -0.221075 | 1.584366 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
16281 rows × 100 columns