|
|
|
|
Análisis de errores con What-If
PRECAUCIÓN 😱: El tema presentado en esta sección está clasificado como avanzado. El entendimiento de este contenido es totalmente opcional.
What-If (también conodido como WIT) es una herramienta que provee una simple interfaz de usuario para exploración y entendimiento de modelos de aprendizaje automático entrenados. Se trata de un plug-in para Tensorboard que nos permite ejecutar el modelo sobre un conjunto de datos para luego evaluar de forma visual sus resultados. Adicionalmente nos permite editar cada una de las muestras sobre las que ejecutamos el modelo para investigar el efecto que tiene sobre el modelo.
Esta herramienta se puede utilizar en modelos que cumplan con las siguientes condiciones:
El modelo debe poder ejecutarse utilizando TensorFlow Serving utilizando las APIs
classify,regressopredict.El conjunto de datos de validación debe estar en formato
TFRecord.
IMPORTANTE: Este notebook no puede ser ejecutado en Google Colab. Si no dispone de un ambiente donde ejecutarlo localmente, puede utilizar la opción de demostración que se comenta en ¿Tiene problemas para instalar los componentes necesarios para usar what-if?
Utilizar WIT para el análisis de errores
Instalando TensorFlow Serving
Como requerimiento para utilizar WIT, necesitamos instalar TensorFLow Serving. En Ubuntu podemos hacerlo de la siguiente forma. Para otras instalaciones revise la guia de instalacion en https://www.tensorflow.org/tfx/serving/setup. En la mayoria de los casos le recomendamos la instalación vía Docker.
[ ]:
!sudo apt-add-repository 'deb http://storage.googleapis.com/tensorflow-serving-apt stable tensorflow-model-server tensorflow-model-server-universal'
!sudo apt update
!supo apt install tensorflow-model-server
¿Tiene problemas para instalar los componentes necesarios para usar what-if?
Para inspeccionar este ejemplo sin necesidad de instalar los componentes, puede acceder al sitio de demostración donde le permite interactuar con la interfaz desde su navegador. Tenga en cuenta que esta versión no le permite explorar su propio conjunto de datos ya que solo funciona para el conjunto de datos que se propone en el ejemplo.
Sobre el conjunto de datos del censo UCI
El conjunto de datos del censo de la UCI es un conjunto de datos en el que cada registro representa a una persona. Cada registro contiene 14 columnas que describen a una una sola persona, de la base de datos del censo de Estados Unidos de 1994. Esto incluye información como la edad, el estado civil y el nivel educativo. La tarea es determinar si una persona tiene un ingreso alto (definido como ganar más de $50 mil al año). Esta tarea, dado el tipo de datos que utiliza, se usa a menudo en el estudio de equidad, en parte debido a los atributos comprensibles del conjunto de datos, incluidos algunos que contienen tipos sensibles como la edad y el género, y en parte también porque comprende una tarea claramente del mundo real.
Sobre el modelo
Utilizaremos un modelo entrenado en este conjunto de datos. El mismo lo puede acceder desde datasets/uci_census/model/1
[ ]:
!wget https://santiagxf.blob.core.windows.net/public/datasets/uci_census.zip \
--quiet --no-clobber
!mkdir -p datasets/uci_census
!unzip -qq uci_census.zip -d datasets/uci_census
Inspeccionando el modelo, podemos ver que recibe como entrada un vector de longitud no especificada y como salida la clase y la probabilidad asociada:
[6]:
!saved_model_cli show --dir datasets/uci_census/model/1 --tag serve --signature classification
2021-10-17 12:23:09.841674: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2021-10-17 12:23:09.841748: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
The given SavedModel SignatureDef contains the following input(s):
inputs['inputs'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: input_example_tensor:0
The given SavedModel SignatureDef contains the following output(s):
outputs['classes'] tensor_info:
dtype: DT_STRING
shape: (-1, 2)
name: linear/head/Tile:0
outputs['scores'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 2)
name: linear/head/predictions/probabilities:0
Method name is: tensorflow/serving/classify
Iniciar TensorFlow Serving
Para que nuestro modelo pueda ser consumido por WIF, necesitamos ponerlo a funcionar en una URL. Lo haremos en el puerto 8500. Ejecute el siguiente codigo en una consola:
nohup tensorflow_model_server \
--port=8500 \
--rest_api_port=8501 \
--model_name=uci_income \
--model_base_path="$PWD/datasets/uci_census/model/1" >server.log 2>&1
Verifiquemos que el modelo está corriendo:
[9]:
!curl http://localhost:8501/v1/models/uci_income
{
"model_version_status": [
{
"version": "1",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": ""
}
}
]
}
Iniciamos TensorBoard con WIT
Iniciaremos Tensorboard en el navegador. Por defecto tensorboard se ejecuta en el puerto 6006:
[ ]:
!nohup tensorboard --logdir /tmp/logs
Una vez que esté ejecutandose, deberemos navegar a la URL https://localhost:6006 que es donde se ejecuta Tensorboard. En Tensorboard seleccione la opción de What-If en el menú desplegable de herramientas disponibles (barra de herramientas superior). Cuando lo seleccione, deberá configurar la herramienta.
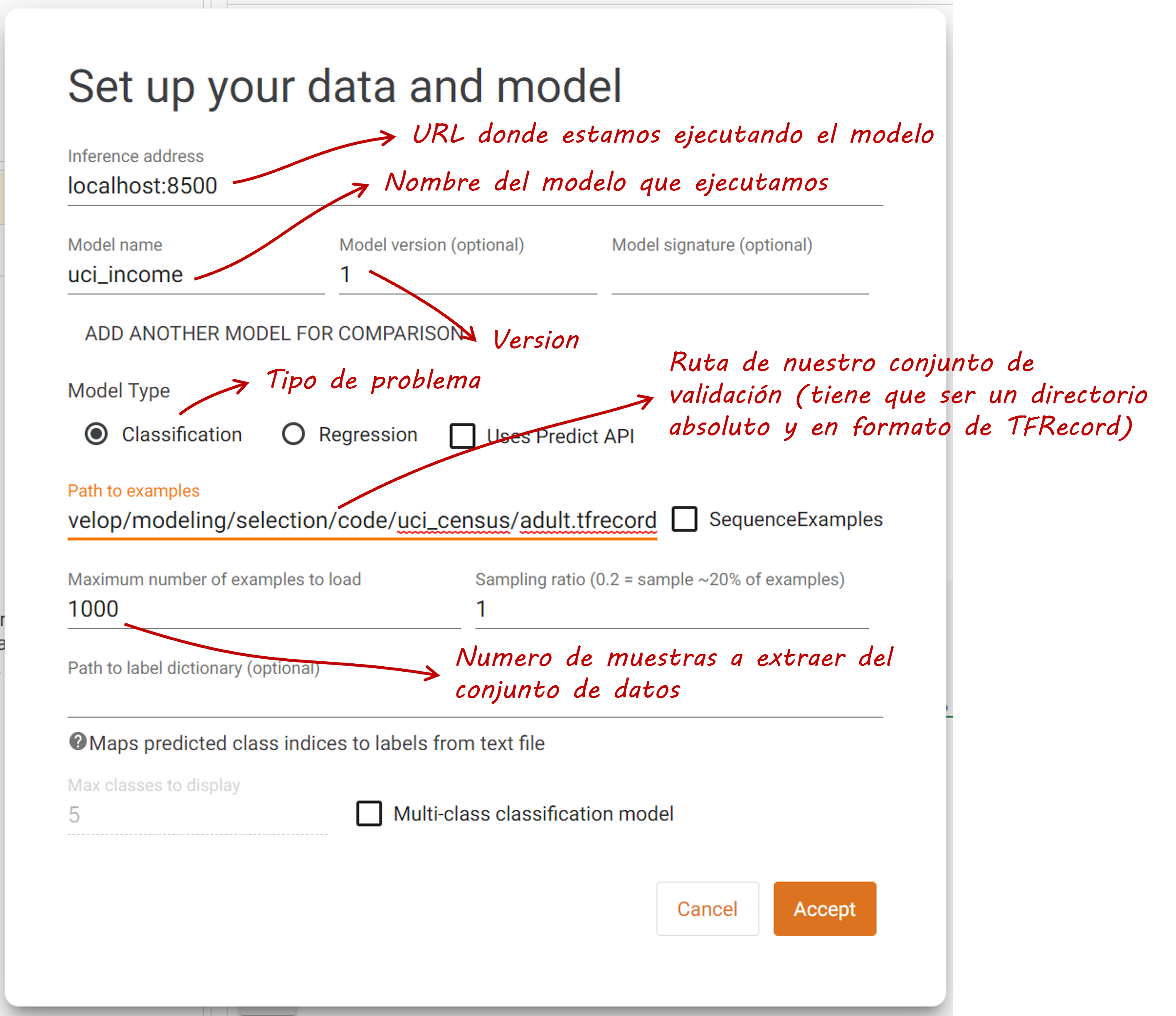
Para configurarla necesitamos:
La URL donde se ejecuta nuestro modelo con TensorFlow Serving: En nuestro caso es http://localhost:8500.
El nombre del modelo que estamos ejecutando. Esto coincide con el nombre que utilizamos cuando ejecutamos TensorFlow Serving. En nuestro caso uci_income
La versión del modelo. Por defecto utilizamos la versión 1
El tipo de problema a resolver
Ruta (absoluta) donde se encuentra el set de datos de validación. Este set debe estar en formato
TFRecord.
Explorando los datos
Una vez que hemos configurado la herramienta, lo primero que vemos es el conjunto de datos visualizado como puntos individuales en Facets Dive. Cada punto está coloreado por la categoría que el modelo le asignó. Los puntos azules representan a las personas que el modelo infirió con ingresos altos y los puntos rojos representan a aquellos con bajos ingresos. Además, los puntos se posicionan de arriba hacia abajo de acuerdo al nivel de confianza que tiene el modelo de que la persona tiene
ingresos altos, lo que se denomina inference score.
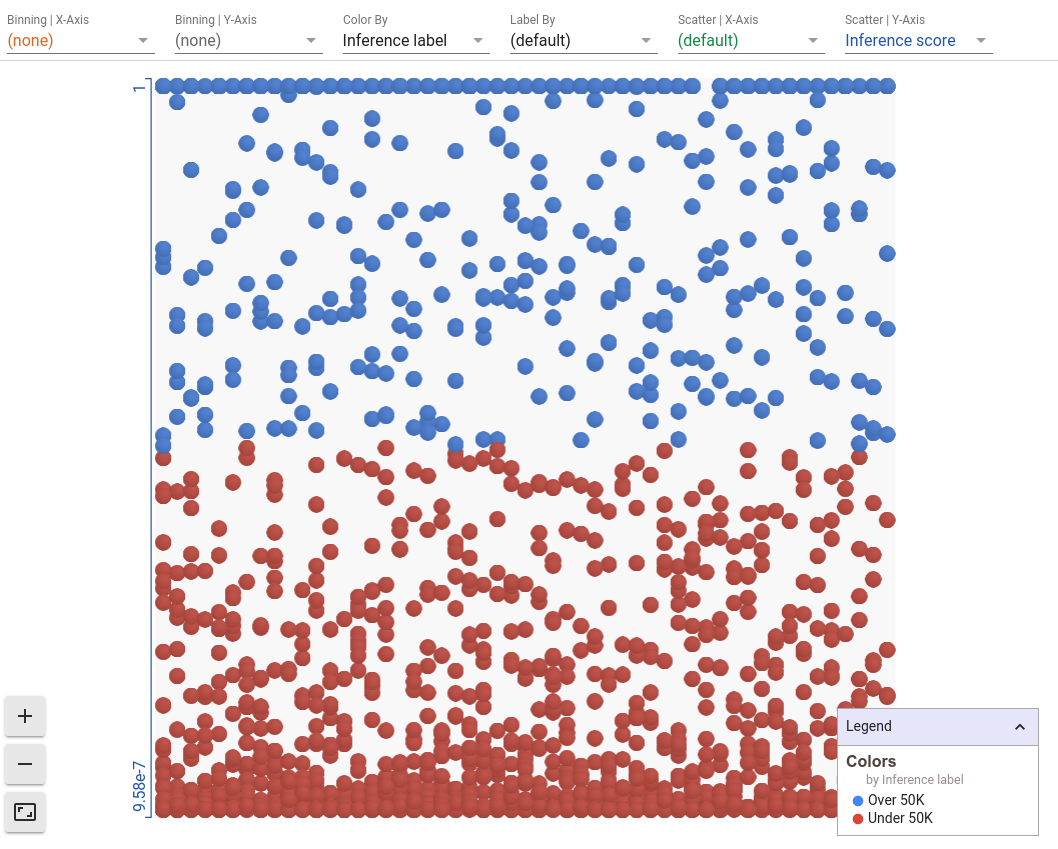
De aquí es claro ver que hay más puntos rojos que puntos azules, lo que significa que el modelo predice más personas con ingresos bajos que con ingresos altos. Muchos puntos se agrupan tanto en la parte inferior como en la parte superior de la visualización, lo que significa que nuestro modelo suele estar muy seguro de que una persona tiene ingresos bajos o altos.
Facets Dive
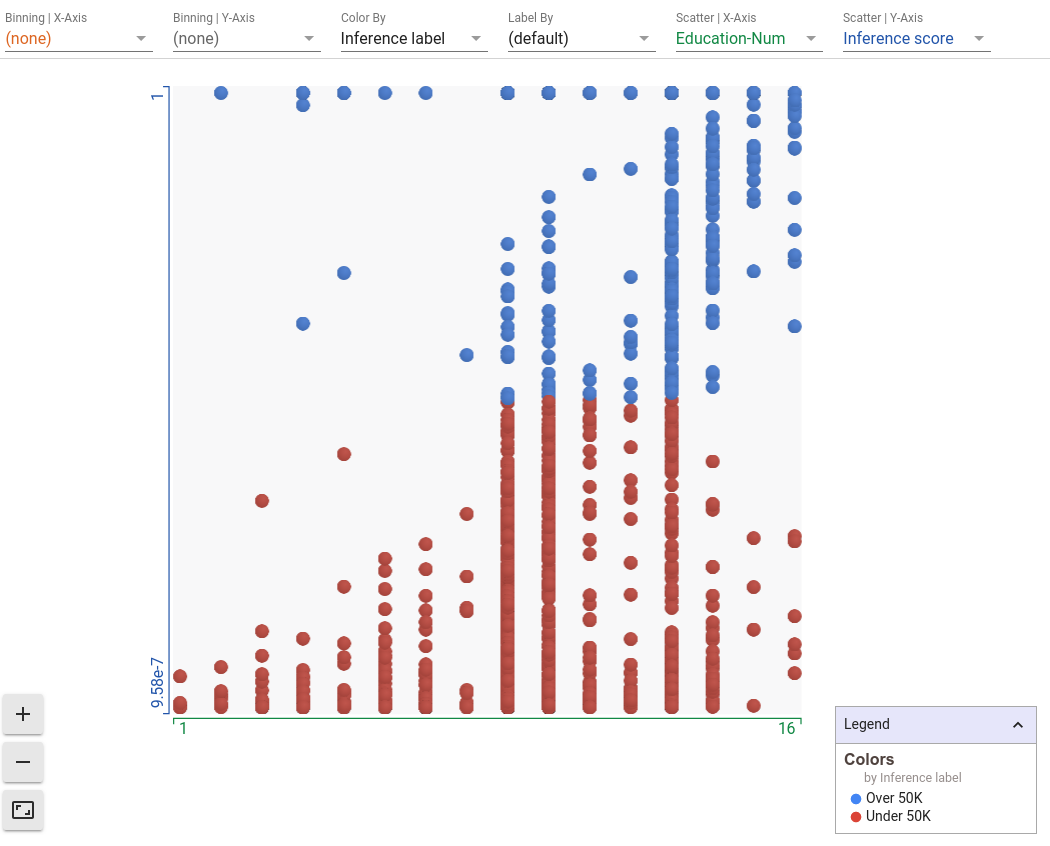
Podemos configurar otros predictores en el eje x, como ser el nivel de educación. En nuestro conjunto de datos, esto se describe como un número que representa el último año escolar que completó una persona. Al hacerlo, inmediatamente podemos ver que a medida que aumenta el nivel de educación (a medida que avanzamos hacia la derecha en la trama), aumenta el número de puntos azules. Por lo tanto, el modelo está aprendiendo claramente que existe una correlación positiva entre el nivel educativo y los ingresos altos.
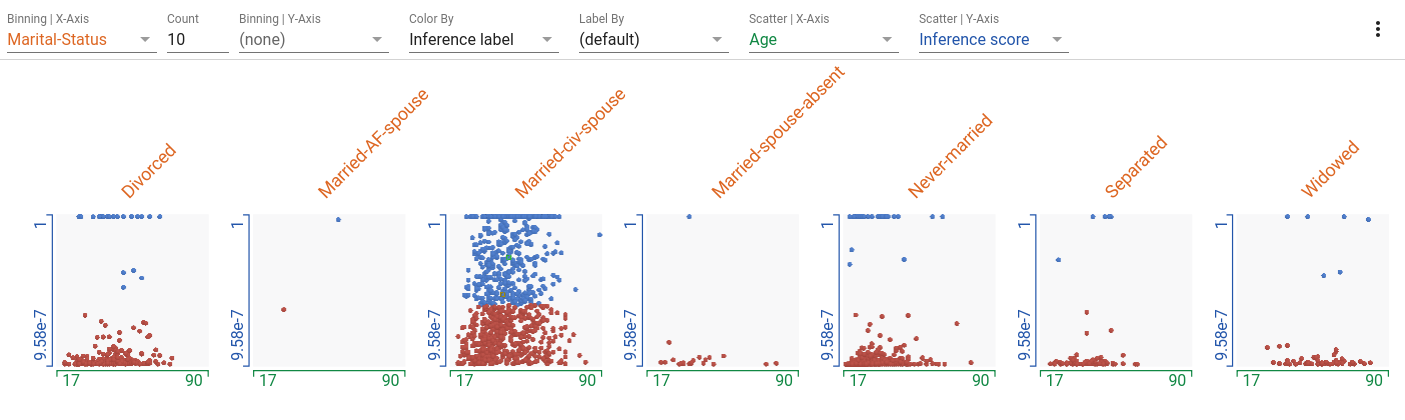
Facets Dive es increíblemente flexible y puede crear múltiples visualizaciones interesantes a través de su capacidad para agrupar, dispersar y colorear puntos de datos. Si bien las posibilidades son infinitas, aquí hay una pequeña lista de visualizaciones que pueden resultarle interesantes con este modelo.
Editando instancias de datos
Al hacer clic en un punto, los detalles del punto de datos aparecen en el panel del editor de puntos a la izquierda de la visualización, incluidos sus predictores y sus predicción. Para el punto de la imagen que sigue, la puntuación de inferencia para la clase positiva (ingresos altos) fue 0,472 y la puntuación para la clase negativa (ingresos bajos) fue 0,528. Estos puntajes están muy cerca del umbral de decisión de 0.5 que usa inicialmente la herramienta. Para un punto tan cerca del umbral,
probablemente podríamos cambiar uno de sus predictores para hacer que la predicción cruce el umbral de 0,5. Intentemos cambiar la edad de 42 a 48 y luego corramos el modelo presionando Run inference.
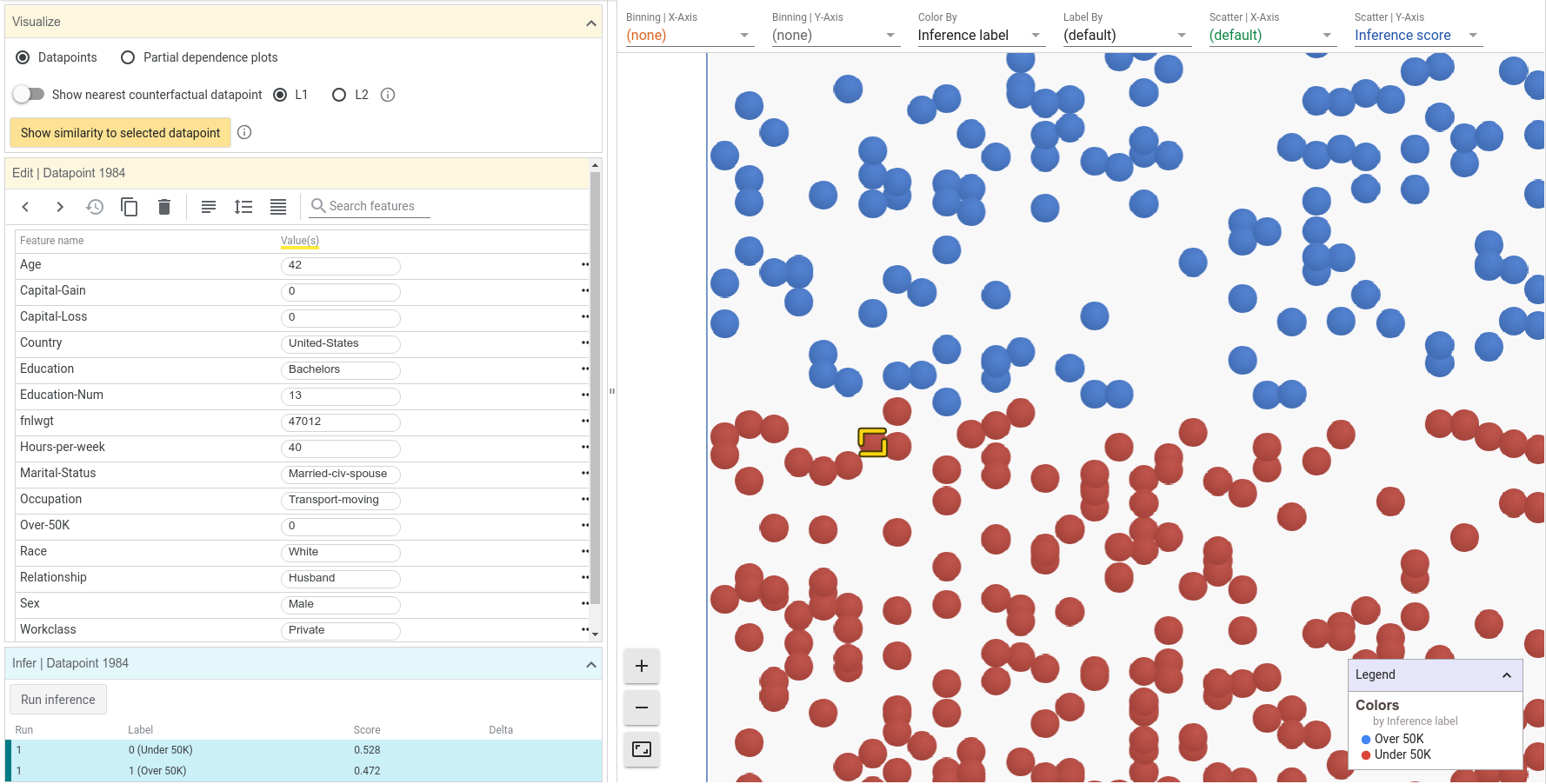
Counterfactuals
Un Counterfactual es una instancia de datos que es similar a otra instancia de datos (es decir, que comparten una posición cercana en el espacio de representaciones) pero cuya predicción es opuesta a la de la instancia original. El contrafactual más cercano es el punto más similar que cumple con esta definición. Para el punto seleccionado en el ejemplo, que se clasificó como ingresos bajos, el contrafactual más cercano es la persona más similar que el modelo clasificó como ingresos altos.
WIT puede encontrar el contrafactual más cercano usando una de dos formas de calcular la similitud entre los puntos de datos utilizando la distancia L1 o L2. Si buscamos el contrafactual más cercano usando la distancia L1 veremos dos puntos de datos que se comparan uno al lado del otro. El texto verde representa características en las que los dos puntos de datos difieren. En este caso, el contrafactual más cercano es una persona de mayor edad y que tiene una ocupación diferente, pero por
lo demás es idéntico.
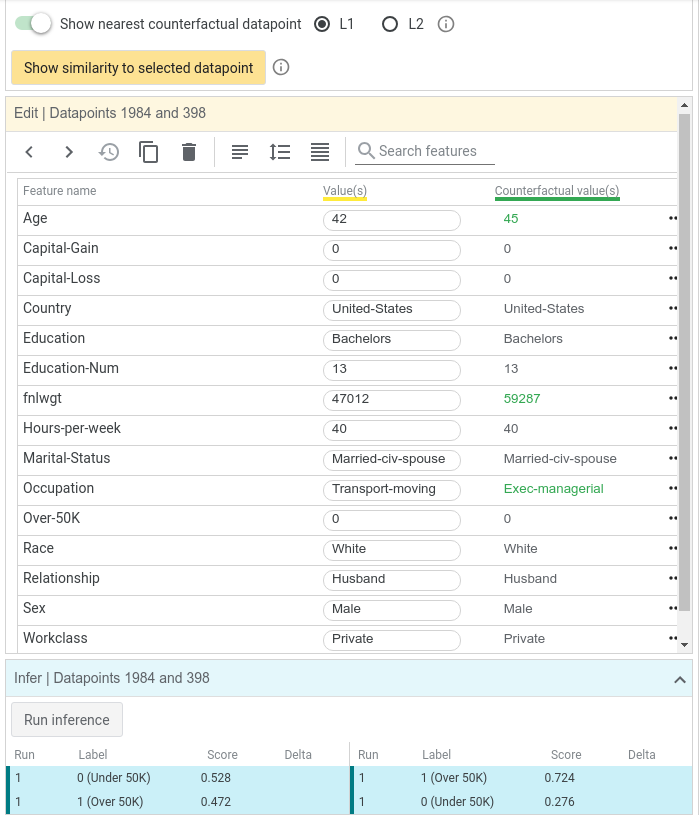
Gráficos de dependencia parcial
Los gráficos de dependencia parcial (Partial Dependency Plot) permiten un enfoque basado en principios para explorar cómo los cambios en un punto afectan la predicción del modelo. Cada gráfico de dependencia parcial muestra cómo cambia la puntuación de clasificación positiva del modelo a medida que se ajusta una sola característica de los datos.
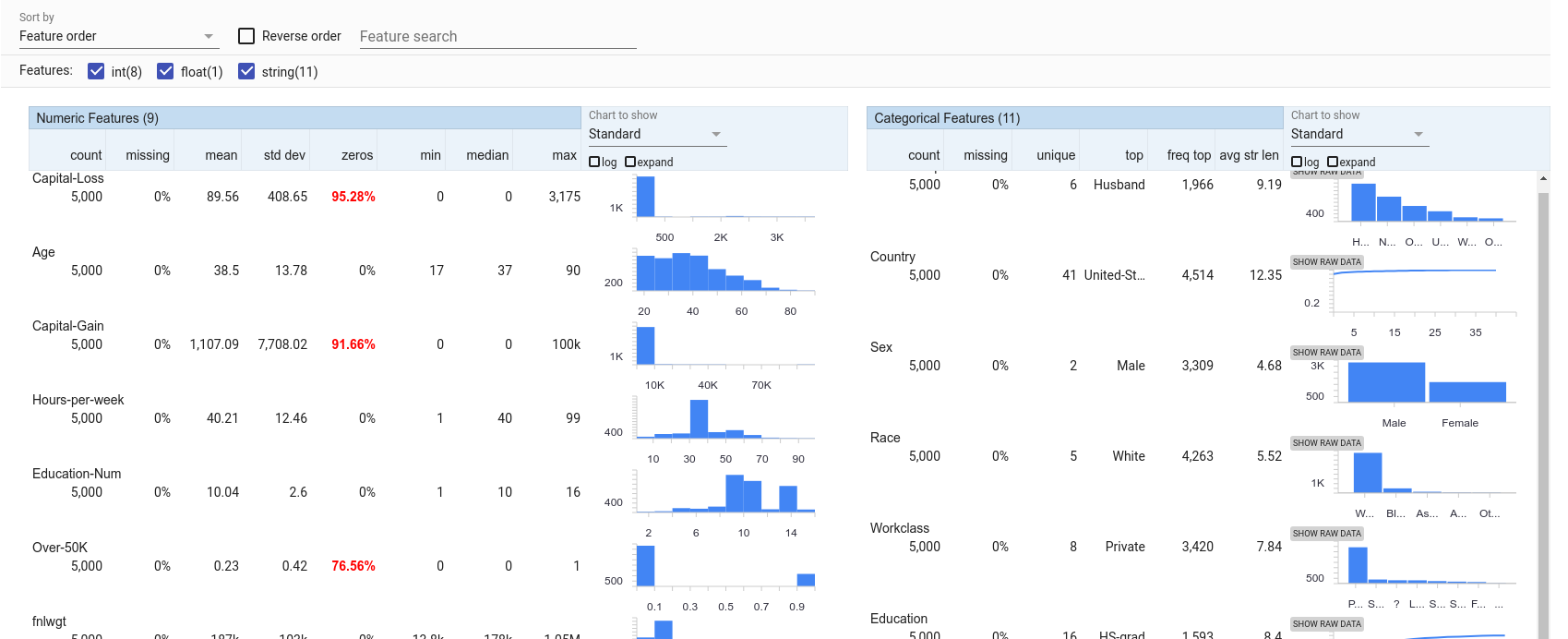
Resumen de predictores
En la pestaña Features, podemos ver la distribución de valores para cada predictor en el conjunto de datos. Podemos ver que de los 1,000 puntos de datos de prueba, más de 70% son de hombres y más de 95% son de raza blanca. Las mujeres y las minorías parecen estar infrarrepresentadas en este conjunto de datos. Eso puede llevar a que el modelo no aprenda una representación precisa del mundo en el que está tratando de hacer predicciones. Es más probable que las predicciones sobre los grupos
menos representados sean inexactas que las predicciones sobre los grupos que están sobrerepresentados.
Las características de esta visualización se pueden ordenar según una serie de métricas diferentes, incluida la falta de uniformidad. Con esta clasificación, las características que tienen la mayor cantidad de distribuciones no uniformes se muestran primero. Para las características numéricas, la ganancia no es muy uniforme, y la mayoría de los puntos la tienen configurada en 0, pero un pequeño número de personas tiene ganancias distintas de cero, hasta un máximo de 100,000. Para las características categóricas, el país es el menos uniforme ya que la mayoría de las personas provienen de EE. UU. Sin embargo, hay una larga cola de otros 40 países que no están bien representados.
Performance y análisis de errores
Podemos utilizar la WIT para identificar la performance del modelo en diferentes secciones del conjunto de datos. Si accedemos a la solapa Performance & Fairness podemos configurar la visualización de la performance a lo largo de diferentes predictores. También podemos cambiar el costo de un falso positivo versus el costo de un falso negativo para ayudarnos a estimar cual es la mejor configuración del umbral de decisión.
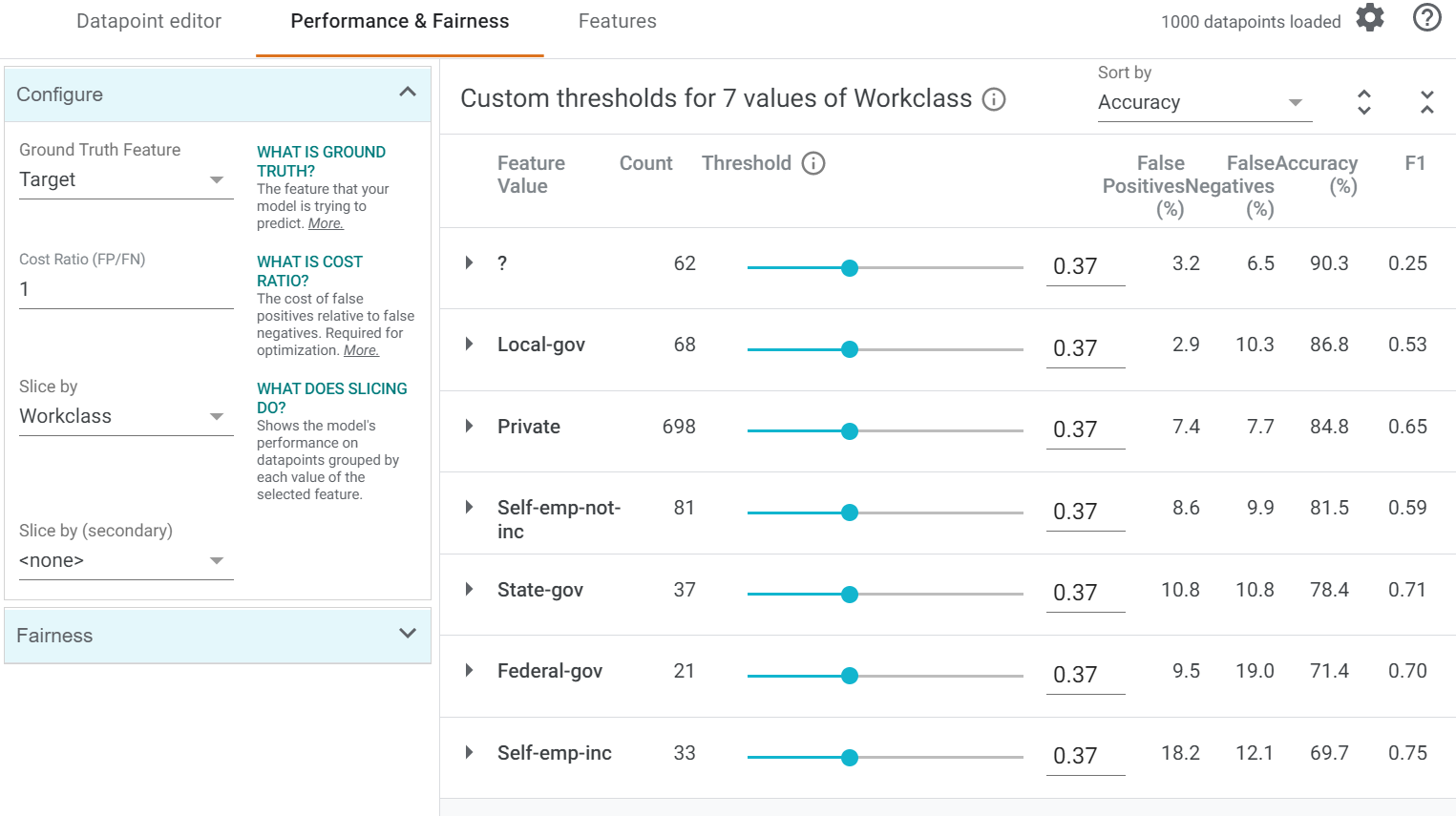
En el ejemplo podemos ver que la performance del modelo para el tipo de trabajador self-emp-inc es mucho más baja comparado con el resto, indicandonos que o bien el modelo tiene problemas en clasificarlos correctamente o que no tenemos suficientes datos sobre los cuales aprender.