Sesgo-varianza
Enfoque clásico
El dilema o problema sesgo-varianza es el conflicto al tratar de minimizar simultáneamente dos fuentes de error:
- El sesgo (bias):
Es el error que se genera por suposiciones erróneas o inexactas en el algoritmo de aprendizaje. Un sesgo alto puede hacer que el modelo pierda detalles relevantes entre los predictores y la variable que queremos predecir (underfitting)
- La varianza (variance):
Es el error asociado a la sensibilidad del modelo a pequeñas fluctuaciones en el set de entrenamiento. Una varianza alta puede hacer que un algoritmo modele el ruido en los datos de entrenamiento, en lugar de la información subyacente (overfitting).
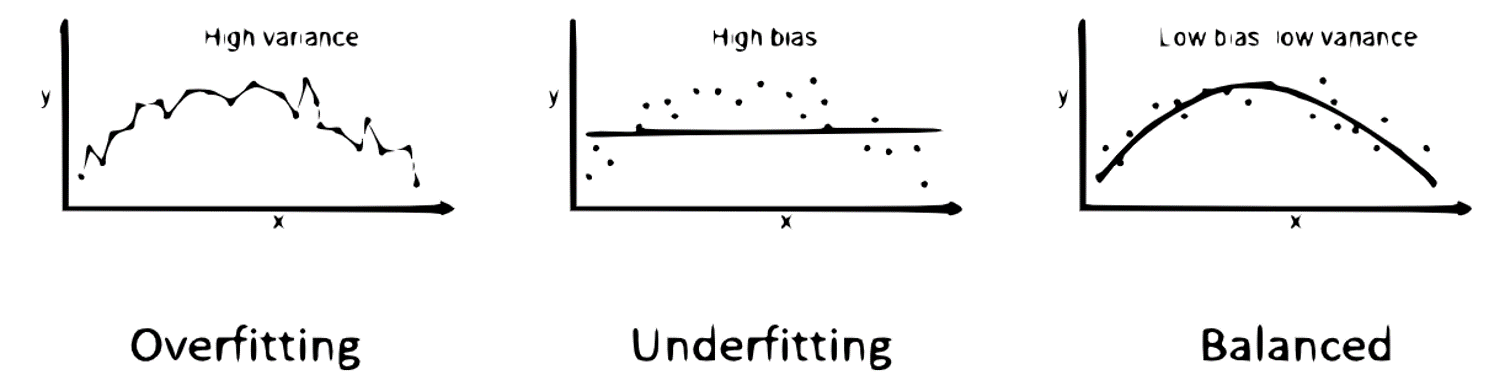
Sesgo-varianza
Enfoque moderno
Utilizando un enfoque más moderno o inspirado en las técnicas de aprendizaje profundo, dejamos de hablar de la tensión entre el sesgo y la varianza para hablar en su lugar de la relación entre la complejidad del modelo y el error, detectando las situaciones:
- Underfitting:
Cuando el modelo no puede reducir el error tanto en el set de entrenamiento como en el de evaluación. La causa es una capacidad insuficiente del modelo; es decir, no es lo suficientemente potente como para adaptarse a las complejidades subyacentes de las distribuciones de datos.
- Overfitting:
Cuando el modelo es tan poderoso que se ajusta demasiado bien al set de entrenamiento, mientras luego no puede generalizarlo al set de evaluación.
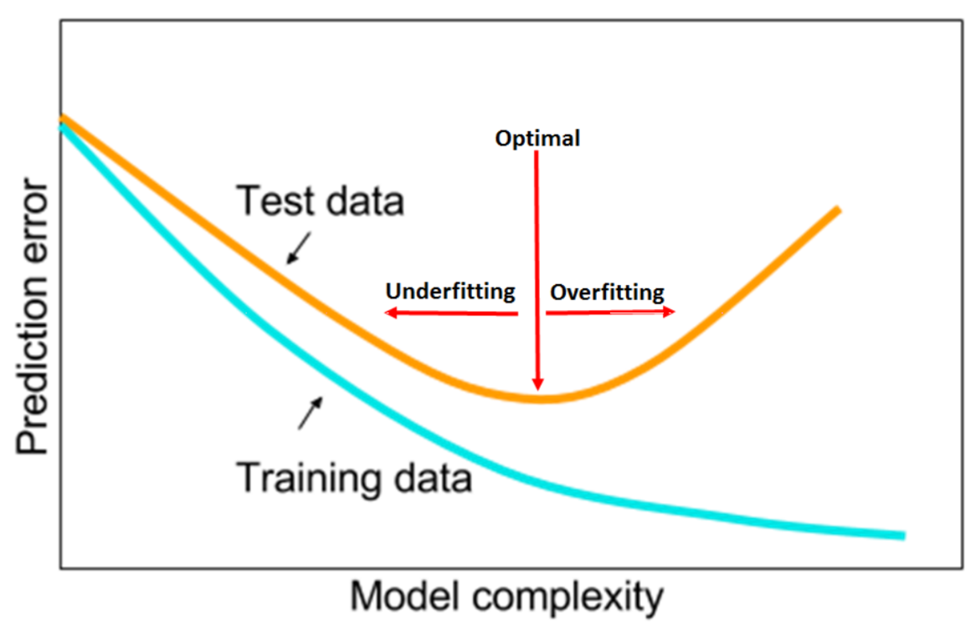
Sesgo-varianzaComplejidad del modelo vs error
En palabras simples, si el error es alto en el conjunto de entrenamiento y en el conjunto de validación, entonces tenemos un alto sesgo. Si bien el conjunto de entrenamiento es bueno pero en el conjunto de validación es malo, tenemos una gran varianza. El sesgo esencialmente implica que la salida es mala para todos los datos. La varianza implica que la salida es buena para algunos datos y mala para el resto.
Uno puede decir intuitivamente que si tenemos un sesgo alto, significa que estamos haciendo Underfitting. Esto podría deberse a que algunas característica en particular no son lo suficientemente buenas o que el modelo en sí no es lo suficientemente portente. En base a esto, podemos actualizar la solución para mejorar el rendimiento, mejorando las características o el modelo en sí. Por otro lado, una alta variación significa que no lo estamos entrenando lo suficiente. Necesitamos más datos o necesitamos un procesamiento mucho mejor de los datos disponibles. Con esto, podríamos entrenar un mejor modelo.
Reduciendo el sesgo
Un modelo de aprendizaje automático solo puede aprender de los datos disponibles. Esto quiere decir que algunos errores son inevitables en los datos de entrada. Tal limitación se llama sesgo inevitable y es importante tenerlo presente. Por ejemplo, si nuestra variable a predecir es una medición que está en metros, sería dificil pensar que el modelo alcance una performance mejor que el error de medición del intrumento que utilizamos para generar las etiquetas o anotaciones. Realizando un Análisis de errores, podemos intentar identificar la causa principal del error. Si nuestro análisis nos dice que el sesgo evitable es la principal fuente de error, podemos mitigarlo:
Aumentar el tamaño del modelo
Utilizar más cantidad de predictores o características
Reducir la cantidad de regularización del modelo
Evitar un mínimo local utilizando momentum o random starts
Cambiar la arquitectura del modelo
Reduciendo la varianza
Si el análisis de error señala que la principal causa del error es una alta varianza, podemos usar una de estas técnicas para reducirla:
Agregar mas datos de entrenamiento
Agregar regularización
Detener el proceso de entrenamiento antes
Reducir la cantidad de predictores
Reducir el tamaño del modelo
Cambiar la arquitectura del modelo