|
|
|
|
Análisis de errores en conjunto de validación
Introducción
El análisis de errores es el proceso para identificar, observar y diagnosticar predicciones erróneas de un modelo de aprendizaje automático, ayudandonos a comprender las áreas con fortalezas o debilidades de un modelo. Cuando decimos que «la precisión del modelo es del 90%», puede que no sea uniforme en todos los subgrupos de datos o puede haber algunas condiciones en los datos de entrada en las que el modelo falla más. Por lo tanto, es importante someter las métricas a una revisión más profunda para poder mejorarlo.
En este ejemplo veremos como utilizar la herramienta de Error Analysis provista en el Responsable AI Toolbox. Para mas detalles sobre esta herramienta visite: https://github.com/microsoft/responsible-ai-toolbox.
Utilizando el análisis de errores en el problema censo de la UCI
Instalación
Utilizaremos las librerías interpret-community, raiwidgets y error-analysis.
Para ejecutar este ejemplo, necesitaremos instalar las librerias interpret-community, raiwidgets y error-analysis y lightgbm:
[ ]:
!pip install rai-core-flask raiutils --quiet
!pip install statsmodels==0.14.5 numpy==1.26.2 erroranalysis==0.5.5 responsibleai==0.36.0 interpret-community==0.32.0 interpret-core==0.6.6 lightgbm raiwidgets==0.36.0 scikit-learn==1.5.1 shap==0.46.0 fairlearn interpret ml_wrappers econml sparse semver dice_ml --no-deps --quiet
IMPORTANTE: Reinicie el kernel desde el menu
Runtime(Google Colab) oKernel(Jupyter) luego de realizar la instalación. Es posible que se mencionen errores de resolución de paquetes durante la instalación. Puede ignorarlos.
Sobre el conjunto de datos del censo UCI
El conjunto de datos del censo de la UCI es un conjunto de datos en el que cada registro representa a una persona. Cada registro contiene 14 columnas que describen a una una sola persona, de la base de datos del censo de Estados Unidos de 1994. Esto incluye información como la edad, el estado civil y el nivel educativo. La tarea es determinar si una persona tiene un ingreso alto (definido como ganar más de $50 mil al año). Esta tarea, dado el tipo de datos que utiliza, se usa a menudo en el estudio de equidad, en parte debido a los atributos comprensibles del conjunto de datos, incluidos algunos que contienen tipos sensibles como la edad y el género, y en parte también porque comprende una tarea claramente del mundo real.
Descargamos el conjunto de datos
[1]:
!wget https://santiagxf.blob.core.windows.net/public/datasets/uci_census.zip \
--quiet --no-clobber
!mkdir -p datasets/uci_census
!unzip -qq uci_census.zip -d datasets/uci_census
Lo importamos
[2]:
import pandas as pd
import numpy as np
train = pd.read_csv('datasets/uci_census/data/adult-train.csv')
test = pd.read_csv('datasets/uci_census/data/adult-test.csv')
Entrenando un modelo para explorar
Preparando nuestros conjuntos de datos
[4]:
X_train = train.drop(['income'], axis=1)
y_train = train['income'].to_numpy()
X_test = test.drop(['income'], axis=1)
y_test = test['income'].to_numpy()
[5]:
classes = train['income'].unique().tolist()
features = X_train.columns.values.tolist()
categorical_features = X_train.dtypes[X_train.dtypes == 'object'].index.tolist()
Realizaremos un pequeño preprocesamiento antes de entrenar el modelo:
Imputaremos los valores faltantes de las caracteristicas numéricas con la media
Imputaremos los valores faltantes de las caracteristicas categóricas con el valor
?Escalaremos los valores numericos utilizando un
StandardScalerCodificaremos las variables categóricas utilizando
OneHotEncoder
[6]:
from typing import Tuple, List
import sklearn
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
def prepare(X: pd.DataFrame) -> Tuple[np.ndarray, sklearn.compose.ColumnTransformer]:
pipe_cfg = {
'num_cols': X.dtypes[X.dtypes == 'int64'].index.values.tolist(),
'cat_cols': X.dtypes[X.dtypes == 'object'].index.values.tolist(),
}
num_pipe = Pipeline([
('num_imputer', SimpleImputer(strategy='median')),
('num_scaler', StandardScaler())
])
cat_pipe = Pipeline([
('cat_imputer', SimpleImputer(strategy='constant', fill_value='?')),
('cat_encoder', OneHotEncoder(handle_unknown='ignore', sparse_output=False))
])
transformations = ColumnTransformer([
('num_pipe', num_pipe, pipe_cfg['num_cols']),
('cat_pipe', cat_pipe, pipe_cfg['cat_cols'])
])
X = transformations.fit_transform(X)
return X, transformations
X_train_transformed, transformations = prepare(X_train)
X_test_transformed = transformations.transform(X_test)
Entrenamos un modelo basado en lightgbm
[7]:
from lightgbm import LGBMClassifier
clf = LGBMClassifier(n_estimators=5)
model = clf.fit(X_train_transformed, y_train)
[LightGBM] [Info] Number of positive: 7841, number of negative: 24720
[LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.009690 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 781
[LightGBM] [Info] Number of data points in the train set: 32561, number of used features: 95
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.240810 -> initscore=-1.148246
[LightGBM] [Info] Start training from score -1.148246
Ejecutamos el modelo
[8]:
predictions = model.predict(X_test_transformed)
Podemos revisar la performance del modelo:
[9]:
from sklearn.metrics import classification_report
print(classification_report(y_test, predictions))
precision recall f1-score support
<=50K 0.81 1.00 0.90 12435
>50K 0.98 0.25 0.40 3846
accuracy 0.82 16281
macro avg 0.90 0.63 0.65 16281
weighted avg 0.85 0.82 0.78 16281
Tip: En este ejemplo, hemos entrenado un modelo con un numero de estimadores pequeño a proposito para obtener un modelo con sezgo.
Análisis de errores
El análisis de errores nos permite explorar como se distributye el error de las predicciones de nuestro modelo. Una de las ventajas mas interesantes de esta herramienta es que es agnostica del modelo, es decir, que lo podemos aplicar para cualquier tipo de modelo ya que solamente necesitamos proveer los conjuntos de datos de evaluación con las predicciones que realizó el modelo.
Opcionalmente, podemos aumentar la cantidad de muestras en el conjunto de datos de validación utilizando la técnica de oversampling. Esto nos permite que la herramienta de análisis de errores tenga mas instancias para trabajar y por ende generar más opciones para visualización.
test = test.sample(1000, replace=True)En tal caso, recuerde ejecutar las prediciones sobre el conjunto de datos con oversampling:
X_test = test.drop(['income'], axis=1) y_test = test['income'].to_numpy() X_test_transformed = transformations.transform(X_test) predictions = model.predict(X_test_transformed)
Para abrir la herramienta, debemos construir un ErrorAnalysisDashbord:
[ ]:
from raiwidgets import ErrorAnalysisDashboard
from interpret_community.common.constants import ModelTask
ErrorAnalysisDashboard(dataset=X_test,
true_y=y_test,
categorical_features=categorical_features,
features=features,
pred_y=predictions,
model_task=ModelTask.Classification)
Notas:
``dataset`` es el conjunto de datos de evaluación, sin preprocesamiento y sin la variable objetivo.
``true_y`` es el valor verdadero (ground-truth) de la variable a predecir
``pred_y`` es el valor de las predicciones del modelo que estamos evaluando.
``categorical_features``: son los nombres de las columnas que tienen variables de tipo categorica.
``features`` son los los nombres de todas las columnas que utiliza el modelo, categoricas y numeras incluidas.
``model_task`` es el tipo de modelo que construirmos, donde los valores possibles son ``ModelTask.Classification`` o ``ModelTask.Regression``.
¿Ve el tablero en blanco?: Si ejecuta en Google Colab, asegurese de permitir conexiones sobre http (contenido mixto).
¿Sigue sin ver el tablero?: Asegurese de que su conjunto de datos está bien configurado, que no tiene valores faltantes en las columas y que configuró correctamente las variables categoricas.


Una vez ejecutado el comando anterior, debería poder ver la herramienta de exloración de errores:
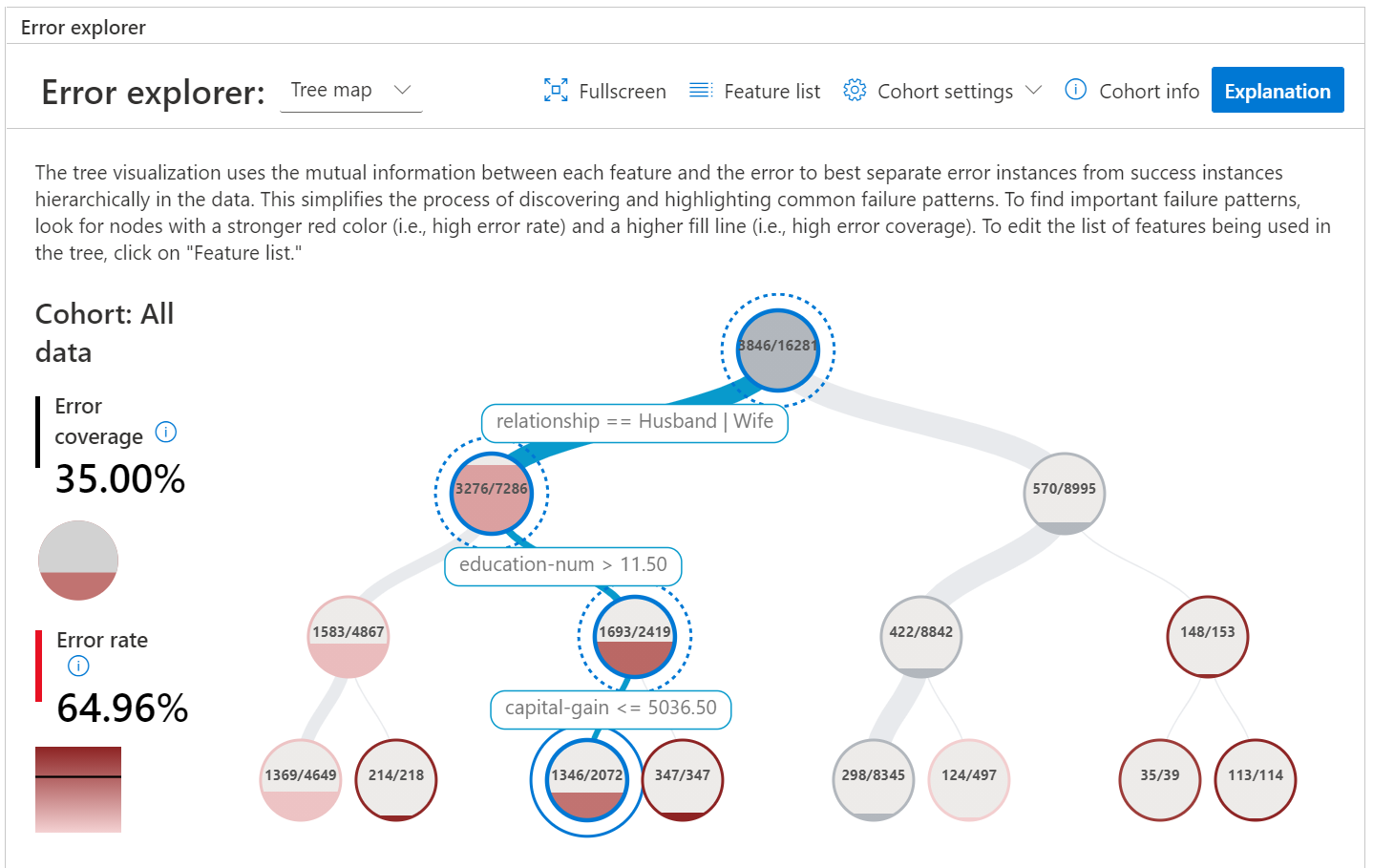
Interpretación
Podemos utilizar este gráfico para explorar la forma en que el modelo comente los errores. Para encontrar patrones, podemos ocmenzar buscando aquellos nodos en el arbol que tienen un color rojo más fuerte, lo que indica que esa combinación de atributos tiene un error alto al clasificarlos. El nivel de llenado del nodo indica que tan representativa es esa combinación de atributos en el conjunto de datos completo
Esto quiere decir que si nos focalizamos en aquellos nodos con color más oscuro y nivel más alto, estamos atacando aquellas áreas donde tenemos más chances de mejorar la performance del modelo. Por ejemplo, en la imagen anterior vemos que cuando la relación es Husband o Wife y la cantidad de años de educación es mayor a 11.5 pero el capital es menor a $ 5035.50, estas instancias tienen una taza de error del 65% y representan el 35% de todos los errores que comete el modelo.
Deberiamos investigar porque nuestro modelo no puede mapear a este tipo de instancias correctamente. Quizás haya un probema en la calidad de datos, una mala recolección, o quizás las características no fueron preprocesadas correctamente.
Instancias con dificultades
Una característica interesante de esta libreria es la capacidad de generar mapas de calor con aquellas combinaciones de atributos donde nuestro modelo tiene problemas. Esto nos permite ver rapidamente donde el modelo tiene inconvenientes en predecir correctamente y desde allí, analizár si el modelo es aceptable cometiendo estos errores o no:
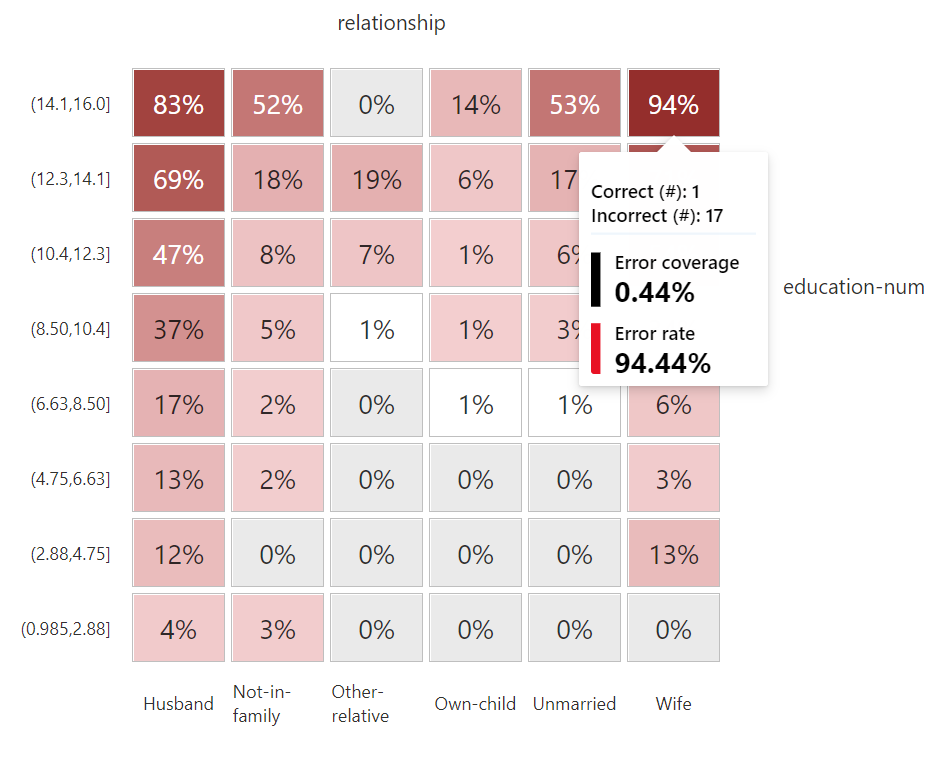
En el ejemplo más arriba estamos comparando los predictores relationship y education-num. Como vemos, el modelo tiene grandes problemas con aquellas personas de más de 14 años de educación y que son mujeres casadas. Solo 1 persona fué clasificada correctamente representando una taza de error del 94%.
Explicaciones
IMPORTANTE: Si ejecuto el tablero anterior, deberá reiniciar la sesión de Colab. Esto se debe solo a restricciones de Colab. En ambientes productivos no debería realizar esta tarea.
Las explicaciones del modelo nos pueden ser útiles a la hora de explorar la importancia de cada uno de los atributos y como son utilizados por el modelo. Para generar las explicaciones del modelo, deberemos constuir un pipeline donde tengamos el preprocesamiento y el modelo propiamente dicho en un mismo objeto ya que las técnicas de explicaciones contemplan tanto las instancias de preprocesamiento como de modelado:
IMPORTANTE: Note que esta técnica requiere proveer el modelo original que genera la predicciones, y por lo tanto no podrá utilizarlo en escenarios donde el modelo fué entrenado en otra herramienta.
[ ]:
model_pipeline = Pipeline(steps=[('preprocessing', transformations),
('model', model)])
Configuramos un objeto para general las explicaciones del modelo basado en el conjunto de datos en el que se entreno:
IMPORTANTE: Note que esta técnica require la creación de un modelo que sea interpretable. Es decir, en lugar de realizar el análisis en el modelo original (el cual podría tener una complejidad arbitraria), el análsis se hace sobre un modelo que pueda ser facilmente interpretable. Para generar este segundo modelo, se utiliza la técnica de Global Model Surrogate la cual consiste en entrenar un modelo alumno que trata de imitar al modelo profesor. Esta técnica claramente no es exacta y no tenemos ninguna garantía de que los errores que comete el modelo alumno son los mismos que los que comete el alumno profesor.
[ ]:
from interpret_community.common.constants import ShapValuesOutput, ModelTask
from interpret_community.mimic import MimicExplainer
from interpret_community.mimic.models import LGBMExplainableModel
explainer = MimicExplainer(model=model,
initialization_examples=X_train,
explainable_model=LGBMExplainableModel,
augment_data=True,
max_num_of_augmentations=10,
features=features,
classes=classes,
model_task=ModelTask.Classification,
transformations=transformations)
X does not have valid feature names, but SimpleImputer was fitted with feature names
X does not have valid feature names, but SimpleImputer was fitted with feature names
Changing the sparsity structure of a csr_matrix is expensive. lil and dok are more efficient.
Changing the sparsity structure of a csr_matrix is expensive. lil and dok are more efficient.
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.075441 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 781
[LightGBM] [Info] Number of data points in the train set: 32561, number of used features: 95
[LightGBM] [Info] Start training from score -1.218004
Generamos las explicaciones del modelo en nuestro conjunto de validación
[ ]:
global_explanation = explainer.explain_global(X_test)
X does not have valid feature names, but SimpleImputer was fitted with feature names
X does not have valid feature names, but SimpleImputer was fitted with feature names
Changing the sparsity structure of a csr_matrix is expensive. lil and dok are more efficient.
Changing the sparsity structure of a csr_matrix is expensive. lil and dok are more efficient.
[ ]:
pd.DataFrame(
data={
"importancia": global_explanation.get_ranked_global_values(),
"feature": global_explanation.get_ranked_global_names()
},
index=global_explanation.global_importance_rank
)
| importancia | feature | |
|---|---|---|
| 5 | 0.360204 | marital-status |
| 4 | 0.170727 | education-num |
| 10 | 0.095830 | capital-gain |
| 0 | 0.072773 | age |
| 12 | 0.050053 | hours-per-week |
| 11 | 0.028772 | capital-loss |
| 6 | 0.017707 | occupation |
| 1 | 0.005299 | workclass |
| 2 | 0.001785 | fnlwgt |
| 7 | 0.001371 | relationship |
| 3 | 0.000489 | education |
| 9 | 0.000050 | gender |
| 8 | 0.000004 | race |
| 13 | 0.000004 | native-country |
Podemos verificar que tan equivalente es el modelo surrogado:
[ ]:
explainer.get_surrogate_model_replication_measure(training_data=X_train)
X does not have valid feature names, but SimpleImputer was fitted with feature names
X does not have valid feature names, but SimpleImputer was fitted with feature names
Changing the sparsity structure of a csr_matrix is expensive. lil and dok are more efficient.
Changing the sparsity structure of a csr_matrix is expensive. lil and dok are more efficient.
X does not have valid feature names, but SimpleImputer was fitted with feature names
X does not have valid feature names, but SimpleImputer was fitted with feature names
Changing the sparsity structure of a csr_matrix is expensive. lil and dok are more efficient.
Changing the sparsity structure of a csr_matrix is expensive. lil and dok are more efficient.
0.9998464420625902
Mostramos el tablero:
[ ]:
from raiwidgets import ErrorAnalysisDashboard
from interpret_community.common.constants import ModelTask
ErrorAnalysisDashboard(explanation=global_explanation,
dataset=X_test,
true_y=y_test,
categorical_features=categorical_features,
features=features,
pred_y=predictions,
model_task=ModelTask.Classification)
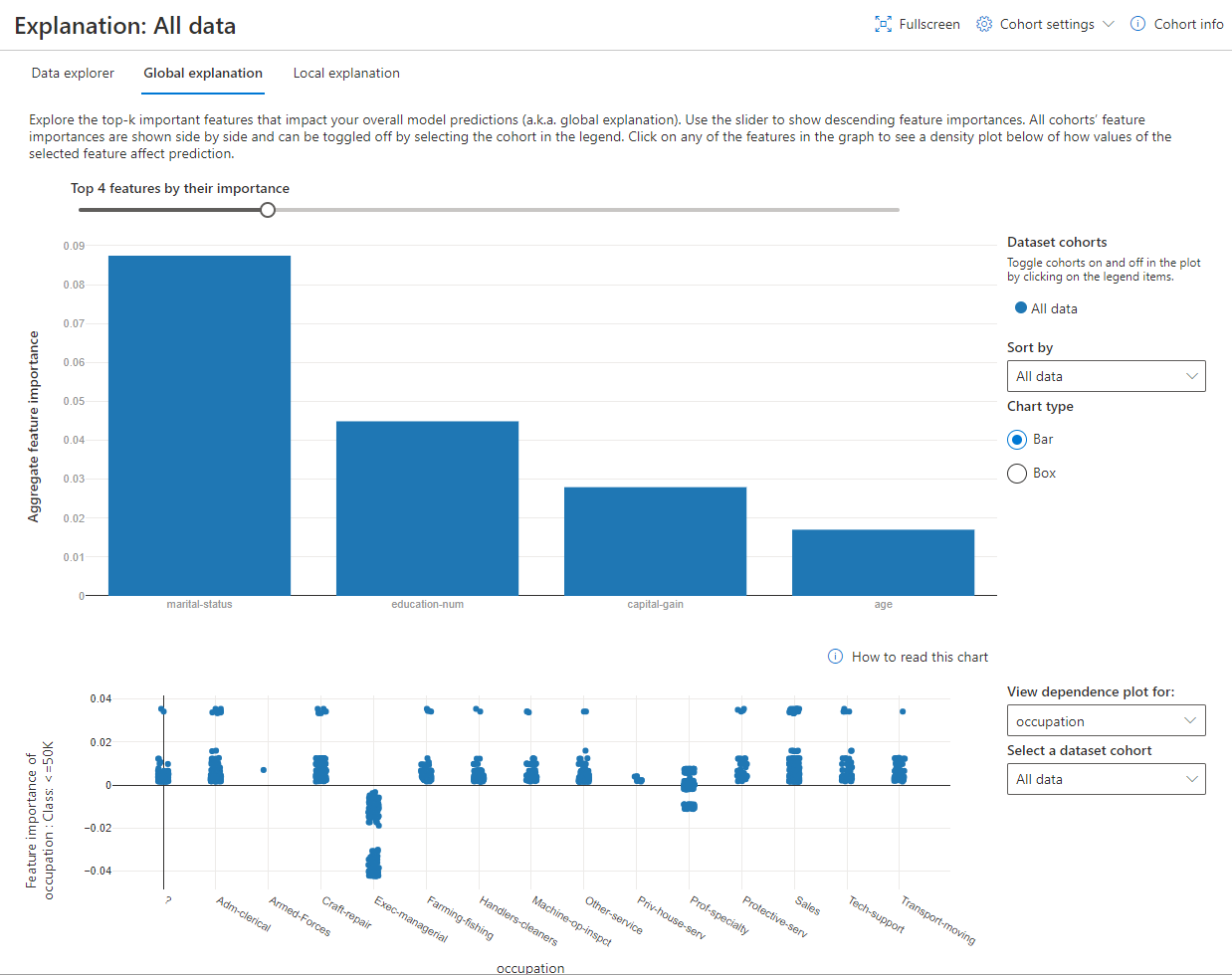
Feature Impotance
En la parte superior del gráfico vemos la importancia de cada uno de los predictores que se utilizaron en el modelo. En este caso, nos indica que marital-status y education son dos de los predictores más importantes para nuestro modelo. El concepto de aque de «importancia» esta atado a que, cuando estos valores cambian, la performance del modelo decrece significativamente.
Dependency plots
En la parte inferior vemos como varia la importancia del predictor ocupation dependiendo de cada uno de todos los varios que obtiene. Este tipo de gráficos se llaman «Dependency plots» y nos permiten ver como la importancia de la clase que queremos predecir cambia a medida que cambian los valores de los predictores.
Por ejemplo, notemos como la importancia de la variable occupation es muy baja cuando cuando el valor es priv-house-serv.