|
|
|
|
Análisis de modelos con TensorFlow Model Analysis
PRECAUCIÓN 😱: El tema presentado en esta sección está clasificado como avanzado. El entendimiento de este contenido es totalmente opcional.
¿Que es TensorFlow Model Analysis?
TensorFlow Model Analysis (TFMA) es una biblioteca de Python para realizar la evaluación del modelo en diferentes segmentos de datos. TFMA es una herramienta muy potente en ambientes productivos ya que realiza sus cálculos de manera distribuida sobre grandes cantidades de datos utilizando Apache Beam, lo cual lo hace altamente escalable. TFMA se puede utilizar para investigar y visualizar el rendimiento de un modelo con respecto a las características del
conjunto de datos.
Para demostrar esta técnica utilizaremos el conjunto de datos del censo UCI.
Instalar TFMA
Instalaremos TFMA como cualquier librería utilizando pip:
pip install tensorflow-model-analysis
Instalaremos aqui esta librería junto con otras necesarias:
[ ]:
!wget https://raw.githubusercontent.com/santiagxf/E72102/master/docs/develop/modeling/selection/code/model_analysis.txt \
--quiet --no-clobber
!pip install -r model_analysis.txt --quiet
Instalación en Jupyter corriendo en su equipo
Para poder utilizar esta librería, deberá instalar las siguientes extensiones. Estas extensiones no son necesarias en Google Colab, pero si para ejecutar este notebook en su instalación local. Los widgets le permitiran explorar las propiedades de su modelo.
[ ]:
!jupyter nbextension install --py --symlink tensorflow_model_analysis --sys-prefix
Habilitamos las extensiones en este notebook:
[1]:
!jupyter nbextension enable --py widgetsnbextension --sys-prefix
!jupyter nbextension enable --py tensorflow_model_analysis --sys-prefix
Enabling notebook extension jupyter-js-widgets/extension...
- Validating: OK
2021-10-26 09:22:53.328925: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2021-10-26 09:22:53.328983: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
Enabling notebook extension tensorflow_model_analysis/extension...
- Validating: OK
Explorando un modelo
Sobre el conjunto de datos del censo UCI
El conjunto de datos del censo de la UCI es un conjunto de datos en el que cada registro representa a una persona. Cada registro contiene 14 columnas que describen a una una sola persona, de la base de datos del censo de Estados Unidos de 1994. Esto incluye información como la edad, el estado civil y el nivel educativo. La tarea es determinar si una persona tiene un ingreso alto (definido como ganar más de $50 mil al año). Esta tarea, dado el tipo de datos que utiliza, se usa a menudo en el estudio de equidad, en parte debido a los atributos comprensibles del conjunto de datos, incluidos algunos que contienen tipos sensibles como la edad y el género, y en parte también porque comprende una tarea claramente del mundo real.
El mismo tiene las siguientes características:
Education-Num
Occupation
Marital-Status
Never-married
Capital-Loss
Race
Country
Workclass
Age
Education
Hours-per-week
Sex
Relationship
Capital-Gain
Target
Sobre el modelo
Utilizaremos un modelo entrenado en este conjunto de datos. El mismo lo puede acceder desde datasets/uci_census/model/1. Lo descargaremos para que esté disponible:
[ ]:
!wget https://santiagxf.blob.core.windows.net/public/datasets/uci_census.zip \
--quiet --no-clobber
!mkdir -p datasets/uci_census
!unzip -qq uci_census.zip -d datasets/uci_census
Utilizando TFMA
[2]:
import tensorflow as tf
import tensorflow_model_analysis as tfma
Como primer paso, deberemos cargar nuestro modelo en un formato que TFMA pueda interpretar. En este caso, utilizaremos un modelo que ya fué entrenado sobre el conjunto de datos utilizando TensorFlow Keras. TFMA soporta modelos de keras, modelos genéricos basados en TF2 signature APIs, y modelos basados en estimadores (estimator) de TensorFlow.
[3]:
eval_shared_model = tfma.default_eval_shared_model(eval_saved_model_path='./datasets/uci_census/model/1',
tags=[tf.saved_model.SERVING])
Para poder utilizar TFMA en nuestro modelo, deberemos generar un objeto de tipo EvalConfig donde insertaremos toda la configuración de cómo evaluar nuestro modelo y bajo que aspectos. Deberemos indicar:
ModelSpec, el cual representa la configuración del modelo que intentamos ejecutar. Aquí deberemos indicar la columna en donde se encuentran los valores verdaderos del conjunto de datos, el nombre de la columna donde nuestro modelo deposita las predicciones y la firma del mismo (en caso de que ubiera más de una.SlicingSpec, las cuales representan todas las formas en las que queremos particionar los datos y obtener métricas al respecto. Siempre habrá unSlicingSpecque representa eloveralldel modelo, y está indicado en la primera posición (vea el siguiente código). Puede indicar especificaciones que cubren más de una columna.MetricsSpec, las cuales representan las métricas que TFMA debe calcular sobre nuestro modelo. Para conocer el listado completo de métricas disponibles puede revisar TensorFlow Metric Analysis Metrics. Algunos puntos a notar:binarize=BinarizationOptionsestá indicado ya que nuestro modelo predice las probabilidades para cada una de las clases (en lugar de predecir alguna clase en particular junto con su nivel de confidencia). Para que TFMA pueda comparar las métricas correctamente es necesario que se compuden contra alguna clase en particular.MetricConfigrepresenta la configuración de cada una de las métricas. Note que es posible comparar la métrica con un modelo anteriormente disponible utilizandoMetricThreshold. Esto es útil para comparar nuestro modelo con su versión anterior.
[4]:
eval_config = tfma.EvalConfig(
model_specs=[tfma.ModelSpec(label_key='Target',
signature_name='classification',
prediction_key='scores')],
slicing_specs=[
tfma.SlicingSpec(), # Overall
tfma.SlicingSpec(feature_keys=["Race"]),
tfma.SlicingSpec(feature_keys=["Occupation"]),
tfma.SlicingSpec(feature_keys=["Race", "Occupation"]),
],
metrics_specs=[
tfma.MetricsSpec(
binarize=tfma.BinarizationOptions(class_ids={ 'values': [0]}),
metrics=[
tfma.MetricConfig(class_name='BinaryAccuracy'),
tfma.MetricConfig(class_name='ExampleCount'),
tfma.MetricConfig(class_name='FalsePositives'),
tfma.MetricConfig(class_name='TruePositives'),
tfma.MetricConfig(class_name='FalseNegatives'),
tfma.MetricConfig(class_name='TrueNegatives'),
])
])
Nota:
BinarizationOptionsfué indicado en esta configuración ya que nuestro modelo predice las probabilidades para cada una de las clases disponibles en lugar de la clase más probable. Para más información sobre esta configuración puede revisar https://github.com/tensorflow/model-analysis/blob/master/g3doc/faq.md
Evaluando el modelo
Una vez que tenemos la configuración lista, evaluamos el modelo contra un conjunto de datos de validación. Note que esté conjunto de datos fué especificado utilizando el formato TFRecord, el cual es un formato altamente eficiente en el ecosistema de TensorFlow:
[ ]:
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
data_location='datasets/uci_census/adult.tfrecord',
output_path='datasets/uci_census/evaluation')
WARNING:absl:Tensorflow version (2.6.0) found. Note that TFMA support for TF 2.0 is currently in beta
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.8 interpreter.
Visualizamos los resultados en Jupyter utilizando la extensión que instalamos al comienzo de este notebook. Aquí indicamos los resultados de la evaluación y la vista en particular que queremos explorar:
[ ]:
tfma.view.render_slicing_metrics(eval_result, slicing_column="Race")
El resultado será algo similar a lo siguiente:

Tip: Si tiene problemas para visualizar este widget, pruebe:
jupyter nbextension disable --py widgetsnbextension
jupyter nbextension enable --py widgetsnbextension
Combinaciones de columnas
[ ]:
tfma.view.render_slicing_metrics(
eval_result,
slicing_spec=tfma.SlicingSpec(
feature_keys=["Race", "Occupation"]))
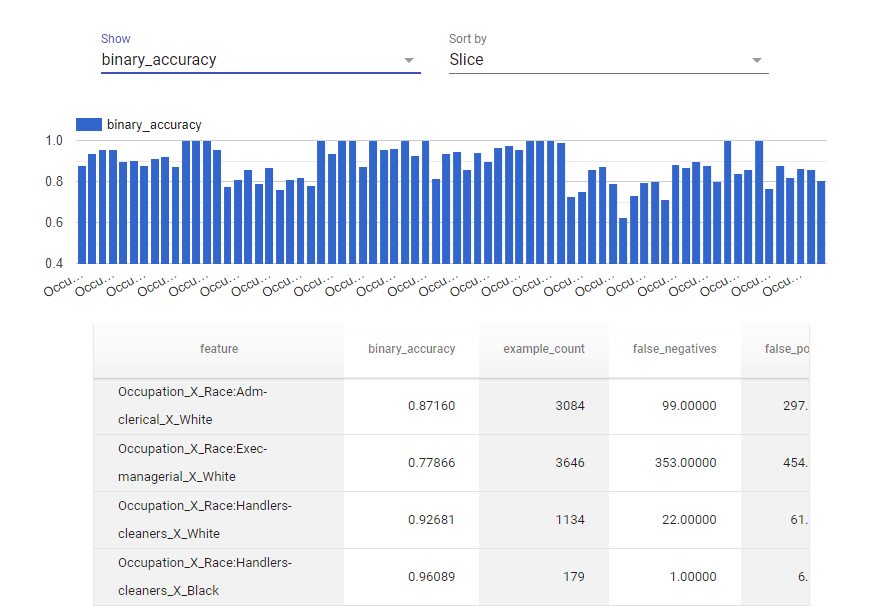
Note que la cantidad de combinaciones puede ser bastante elevada. En general, estaremos interesados en acotarlas especificando algunos valores que estamos queriendo investigar:
[ ]:
tfma.view.render_slicing_metrics(
eval_result,
slicing_spec=tfma.SlicingSpec(
feature_keys=['Occupation'], feature_values={'Race': 'White'}))
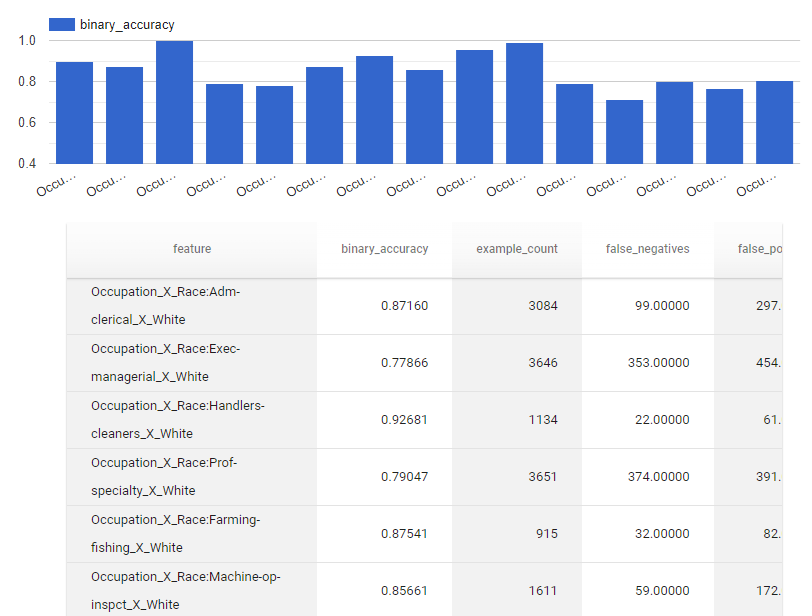
Métricas agregadas
Una forma similar de trabajar con modelos de multiclase o con modelos de clasificación binaria pero que devuelve la probabilidad de cada una de las clases, es utilizar métricas agregredas:
[ ]:
eval_config = tfma.EvalConfig(
model_specs=[tfma.ModelSpec(label_key='Target',
signature_name='classification',
prediction_key='scores')],
slicing_specs=[
tfma.SlicingSpec(), # Overall
tfma.SlicingSpec(feature_keys=["Race"]),
tfma.SlicingSpec(feature_keys=["Occupation"])
],
metrics_specs=[
tfma.MetricsSpec(
metrics=[
tfma.MetricConfig(class_name='BinaryAccuracy'),
tfma.MetricConfig(class_name='BalancedAccuracy'),
tfma.MetricConfig(class_name='ExampleCount'),
tfma.MetricConfig(class_name='FalsePositives'),
tfma.MetricConfig(class_name='TruePositives'),
tfma.MetricConfig(class_name='FalseNegatives'),
tfma.MetricConfig(class_name='TrueNegatives'),
],
aggregate=tfma.AggregationOptions(macro_average=True,
weighted_macro_average=True,
class_weights={
0: 1.0,
1: 10.0,
})
),
])
macro_average computara las métricas de forma macro, es decir, computara la métrica para cada clase y luego tomará el promedio. Utilizando la opción de weighted_macro tendremos la posibilidad de cambiar el peso que representa en el promedio cada clase.
Generando graficos de calibración
Generalmente, para cualquier problema de clasificación, solemos predecir el valor de clase mas probable de ser la verdadera. Sin embargo, a veces, queremos predecir las probabilidades propiamente dichas de cada clase.
Esto es muy útil para la evaluación de un modelo de clasificación. Puede ayudarnos a comprender qué tan «seguro» es un modelo mientras predice una clase y puede ayudarnos a interpretar qué tan decisivo es un modelo de clasificación. Generalmente, los clasificadores que tienen una probabilidad lineal de predecir las etiquetas de cada clase se denominan calibrados. El problema es que no todos los modelos de clasificación están calibrados.
Algunos modelos pueden dar estimaciones deficientes de las probabilidades de clase y algunos ni siquiera admiten la predicción de probabilidad.
Curvas de calibración:
Las curvas de calibración se utilizan para evaluar qué tan calibrado está un clasificador, es decir, cómo difieren las probabilidades de predecir cada clase. El eje x representa la probabilidad promedio predicha en cada contenedor. El eje y es la proporción de positivos (la proporción de predicciones positivas). La curva del modelo calibrado ideal es una línea recta lineal desde (0, 0) que se mueve linealmente.
Curvas de calibración en TFMA
Al igual que con las métricas, los gráficos de calibración se pueden ver por cada predictor. Sin embargo, a diferencia de las métricas, solo se pueden mostrar los gráficos de un valor en particular, por lo que se debe usar tfma.SlicingSpec y debe especificar tanto el nombre como el valor del predictor. Tambiés es posible mostrar las gráficas generales del modelo.
Indicamos en la configuración que necesitamos tener métricas para la característica «Race» con el valor «White»:
[6]:
eval_config = tfma.EvalConfig(
model_specs=[tfma.ModelSpec(label_key='Target',
signature_name='classification',
prediction_key='scores')],
slicing_specs=[
tfma.SlicingSpec(), # Overall
tfma.SlicingSpec(feature_keys=["Occupation"]),
tfma.SlicingSpec(feature_values={ "Race": "White" }),
],
metrics_specs=[
tfma.MetricsSpec(
binarize=tfma.BinarizationOptions(class_ids={ 'values': [0]}),
metrics=[
tfma.MetricConfig(class_name='BinaryAccuracy'),
tfma.MetricConfig(class_name='ExampleCount'),
tfma.MetricConfig(class_name='FalsePositives'),
tfma.MetricConfig(class_name='TruePositives'),
tfma.MetricConfig(class_name='FalseNegatives'),
tfma.MetricConfig(class_name='TrueNegatives'),
tfma.MetricConfig(class_name='Calibration'),
tfma.MetricConfig(class_name='CalibrationPlot'),
tfma.MetricConfig(class_name='ConfusionMatrixPlot'),
])
])
Volvemos a correr el análisis:
[7]:
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
data_location='datasets/uci_census/adult.tfrecord',
output_path='datasets/uci_census/evaluation')
WARNING:absl:Tensorflow version (2.6.0) found. Note that TFMA support for TF 2.0 is currently in beta
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.8 interpreter.
WARNING:apache_beam.io.filebasedsink:Deleting 1 existing files in target path matching:
WARNING:apache_beam.io.filebasedsink:Deleting 1 existing files in target path matching:
WARNING:apache_beam.io.filebasedsink:Deleting 1 existing files in target path matching:
WARNING:apache_beam.io.filebasedsink:Deleting 1 existing files in target path matching:
WARNING:apache_beam.io.filebasedsink:Deleting 1 existing files in target path matching:
[9]:
tfma.view.render_plot(eval_result, slicing_spec=tfma.SlicingSpec(feature_values={"Race": "White"}), class_id=0)
Obtendrá unos graficos similares a los siguientes:

Comparando multiples modelos
TFMA se puede configurar para evaluar varios modelos al mismo tiempo. Por lo general, esto se hace para comparar un nuevo modelo con una línea de base (el modelo que estamos utilizando actualmente por ejemplo) para determinar cuáles son las diferencias en las métricas (por ejemplo, AUC, etc.) en relación con la línea de base. Cuando se configuran los umbrales, TFMA producirá un registro tfma.ValidationResult que indica si el rendimiento coincide con las expectativas.
Exploremos un modelo candidato:
[ ]:
!saved_model_cli show --dir datasets/uci_census/model/2 --tag serve --signature serving_default
2021-10-24 16:23:40.457824: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2021-10-24 16:23:40.457893: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
The given SavedModel SignatureDef contains the following input(s):
inputs['dense_input'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 11)
name: dense_input:0
The given SavedModel SignatureDef contains the following output(s):
outputs['dense_4'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 1)
name: dense_4/Sigmoid:0
Method name is: tensorflow/serving/predict
[ ]:
eval_config = tfma.EvalConfig(
model_specs=[tfma.ModelSpec(name='candidate'
label_key='Target',
signature_name='classification',
prediction_key='scores'),
tfma.ModelSpec(name='baseline',
label_key='Target',
signature_name='classification',
prediction_key='scores'
is_baseline=True)],
slicing_specs=[
tfma.SlicingSpec(), # Overall
tfma.SlicingSpec(feature_keys=["Race"]),
tfma.SlicingSpec(feature_keys=["Occupation"])
],
metrics_specs=[
tfma.MetricsSpec(
metrics=[
tfma.MetricConfig(class_name='BinaryAccuracy',
threshold=tfma.MetricThreshold(
# Verifica que Accuracy no sea menor a 0.7
value_threshold=tfma.GenericValueThreshold(
lower_bound={'value': 0.7}),
# Verifica que el nuevo modelo no haya degradado la perfomrance.
# (candidate - baseline) > -1e-10 or candidate > baseline - 1e-10
change_threshold=tfma.GenericChangeThreshold(
direction=tfma.MetricDirection.HIGHER_IS_BETTER,
absolute={'value': -1e-10}))),
tfma.MetricConfig(class_name='BalancedAccuracy'),
tfma.MetricConfig(class_name='ExampleCount'),
tfma.MetricConfig(class_name='FalsePositives'),
tfma.MetricConfig(class_name='TruePositives'),
tfma.MetricConfig(class_name='FalseNegatives'),
tfma.MetricConfig(class_name='TrueNegatives'),
],
aggregate=tfma.AggregationOptions(macro_average=True,
weighted_macro_average=True,
class_weights={
0: 20.0,
1: 1.0,
})
),
])
[ ]:
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
data_location='datasets/uci_census/adult.tfrecord',
output_path='datasets/uci_census/eval.tfrecord')
WARNING:absl:Tensorflow version (2.6.0) found. Note that TFMA support for TF 2.0 is currently in beta
ERROR:absl:There are change thresholds, but the baseline is missing. This is allowed only when rubber stamping (first run).
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.8 interpreter.
WARNING:apache_beam.io.filebasedsink:Deleting 1 existing files in target path matching:
WARNING:apache_beam.io.filebasedsink:Deleting 1 existing files in target path matching:
WARNING:apache_beam.io.filebasedsink:Deleting 1 existing files in target path matching:
WARNING:apache_beam.io.filebasedsink:Deleting 1 existing files in target path matching:
WARNING:apache_beam.io.filebasedsink:Deleting 1 existing files in target path matching:
[ ]:
tfma.view.render_slicing_metrics(eval_result, slicing_column="Race")